| Author: | |
| Website: | |
| Page title: | |
| URL: | |
| Published: | |
| Last revised: | |
| Accessed: |
Analog transmission is not particularly efficient. When the signal-to-noise ratio of an analog signal deteriorates due to attenuation, amplifying the signal also amplifies noise. Digital signals are more easily separated from noise and can be regenerated in their original state. The conversion of analogue signals to digital signals therefore eliminates the problems caused by attenuation. Pulse Code Modulation (PCM) is the simplest form of waveform coding. Waveform coding is used to encode analogue signals (for example speech) into a digital signal. The digital signal is subsequently used to reconstruct the analogue signal. The accuracy with which the analogue signal can be reproduced depends in part on the number of bits used to encode the original signal. Pulse code modulation is an extension of Pulse Amplitude Modulation (PAM), in which a sampled signal consists of a train of pulses where each pulse corresponds to the amplitude of the signal at the corresponding sampling time (the signal is modulated in amplitude). Each analogue sample value is quantised into a discrete value for representation as a digital code word. Pulse code modulation is the most frequently used analogue-to-digital conversion technique, and is defined in the ITU-T G.711 specification. The main parts of a conversion system are the encoder (the analogue-to-digital converter) and the decoder (the digital-to-analogue converter). The combined encoder/decoder is known as a codec. A PCM encoder performs three functions:
The human voice uses frequencies between 100Hz and 10,000Hz, but it has been found that most of the energy in speech is between 300 Hertz and 3400 Hertz - a bandwidth of approximately 3100 Hertz. Before converting the signal from analog to digital, the unwanted frequency components of the signal are filtered out. This makes the task of converting the signal to digital form much easier, and results in an acceptable quality of signal reproduction for voice communication. From an equipment point of viev, because the manufacture of very precise filters would be expensive, a bandwidth of 4000 Hertz is generally used. This bandwidth limitation also helps to reduce aliasing - aliasing happens when the number of samples is insufficient to adequately represent the analog waveform (the same effect you can see on a computer screen when diagonal and curved lines are displayed as a series of zigzag horizontal and vertical lines).
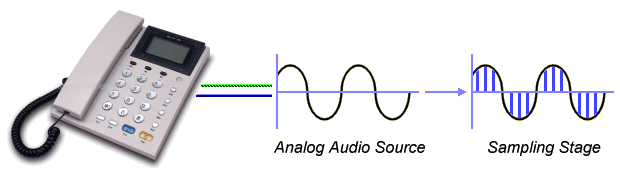
Sampling the analogue signal
Sampling is the process of reading the values of the filtered analogue signal at discrete time intervals (i.e. at a constant sampling rate, called the sampling frequency). A scientist called Harry Nyquist discovered that the original analogue signal could be reconstructed if enough samples were taken. He found that if the sampling frequency is at least twice the highest frequency of the input analogue signal, the signal could be reconstructed using a low-pass filter at the destination.
Quantisation is the process of assigning a discrete value from a range of possible values to each sample obtained. The number of possible values will depend on the number of bits used to represent each sample. Quantisation can be achieved by either rounding the signal up or down to the neares available value, or truncating the signal to the nearest value which is lower than the actual sample. The process results in a stepped waveform resembling the source signal. The difference between the sample and the value assigned to it is known as the quantisation noise (or quantisation error).
Quantisation noise can be reduced by increasing the number of quantisation intervals, because the difference between the input signal amplitude and the quantization interval decreases as the number of quantization intervals increases. This would, however, increase the PCM bandwidth. Uniform quantisation uses equal quantisation levels throughout the entire range of an input analogue signal. The signal-to-noise ratio (SNR), including quantisation noise, is the most important factor affecting voice quality in uniform quantisation. The signal-to-noise ratio is measured in decibels (dB). The higher the signal-to-noise ratio, the better the voice quality. Quantisation noise reduces the signal-to-noise ratio of a signal, so an increase in quantisation noise degrades the quality of a voice signal. Low signals will have a small signal-to-noise ratio and high signals will have a large signal-to-noise ratio. Because most voice signals are relatively low, having better voice quality at higher signal levels is an inefficient way of digitising voice signals. Uniform quantisation was therefore replaced by a non-uniform quantisation process called companding (see below).
Narrowband speech is typically sampled 8000 times per second, and each sample must be quantised. If linear quantisation is used, 12 bits per sample are required, giving a bit rate of 96 kbits per second. This can be reduced using non-linear quantisation, in which 8 bits per sample is sufficient to provide speech quality almost indistinguishable from the original. This results in a bit rate of 64 kbits per second. Two non-linear PCM codecs were standardised in the 1960s - µ-law (mu-law) coding was the standard developed in the United States, while A-law compression was used in Europe. These codecs are still widely used today.
Encoding is the process of representing the sampled values as a binary number in the range 0 to n. The value of n is chosen as a power of 2, depending on the accuracy required. Increasing n reduces the step size between adjacent quantisation levels and hence reduces the quantisation noise. The down side of this is that the amount of digital data required to represent the analogue signal increases.
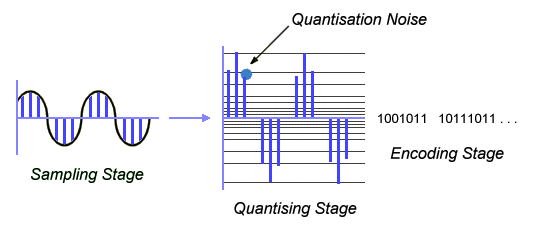
Stages in the analogue-to-digital conversion process
Working with very small signal levels (by comparison with the quantisation interval) can introduce more errors. Companding can be used to increase the accuracy of such signals. This is the process of distorting the analogue signal in a controlled way before quantising takes place, by compressing its larger values at the source and then expanding them at the receiving end. There are two standards used: A-law in Europe, and µ-law in the USA. The term companding was created by combining the terms COMpressing and exPANDING. Input analog signal samples are compressed into logarithmic segments. Each segment is then quantised, and coded using uniform quantisation. The compression process is logarithmic, where the compression increases as the sample signals increase (the larger sample signals are compressed more than the smaller sample signals, causing the quantization noise to increase as the sample signal increases). A logarithmic increase in quantisation noise throughout the dynamic range of an input sample signal gives a signal-to-noise ratio which is almost constant over a wide range of input levels. A rate of eight bits per sample (64 kbits per second) gives a reconstructed signal which is very close the original. The advantages of this system include low complexity and delay, and high-quality reproduction of speech. The disadvantages are a relatively high bit rate and a high susceptibility to channel errors.
Similarities between A-law and µ-law:
Differences between A-law and µ-law:
During the PCM process, the differences between successive input sample signals are minimal. A common technique used in speech coding is to try to predict the value of the next sample from that of the preceding samples. This is possible because of correlations in speech samples due to the effects of the vocal tract and the vibrations of the vocal chords. Differential Pulse Code Modulation (DPCM) schemes quantise the difference between the original and the predicted signals, i.e. the difference between successive values. This means a reduction in the number of bits used per sample over that used for PCM. Using DPCM can reduce the bit rate of voice transmission down to 48 kbps. DPCM can be described as a predictive coding scheme.
The first part of DPCM works like PCM in that the input signal is sampled at a constant sampling frequency, and the samples are modulated using Pulse Amplitude Modulation. The sampled input signal is then stored in a predictor. The predictor sends the stored sample signal it through a differentiator. The differentiator compares the current sample signal with the previous sample signal and sends the difference to the quantising and coding phase of PCM. After quantising and coding, the difference signal is transmitted. At the reciever, the difference signal is dequantised, added to a sample signal stored in a predictor, and sent to a low-pass filter that reconstructs the original input signal. Although DPCM reduces the bit rate for voice transmission, the uniform quantisation used means that large sample signals have a higher signal-to-noise ratio than small sample signals, so voice quality is better at higher signals. Because most signals generated by the human voice are small, voice quality should focus on small signals. Adaptive DPCM was developed to solve this problem.
In the mid 1980's the CCITT standardised an Adaptive Differential Pulse Code Modulation (ADPCM) codec operating at 32 kbps known as G721, resulting in reconstructed speech almost as good as that provided by 64 kbps PCM codecs. This was later followed by ADPCM codecs operating at 16,24 and 40 kbps (G726 and G727). In ADPCM, the predictor and quantiser are adaptive - they change to match the characteristics of the speech being coded. ADPCM adapts the quantisation levels of the difference signal that is generated during the DPCM process. If the difference signal is low, ADPCM reduces the size of the quantisation levels. If the difference signal is high, ADPCM increases the size of the quantisation levels. The quantisation level is thus adapted to the size of the input difference signal, generating a uniform signal-to-noise ratio throughout the dynamic range of the difference signal.
Time division multiplexing is used at local exchanges to combine a number of incoming voice signals onto an outgoing trunk. Each incoming channel is allocated a specific time slot on the outgoing trunk, and has full access to the transmission line only during its particular time slot. Because the incoming signals are analogue, they must first be digitised, because TDM can only handle digital signals. Because PCM samples the incoming signals 8000 times per second, each sample occupies 1/8000 seconds (125 µseconds). PCM is at the heart of the modern telephone system, and consequently, nearly all time intervals used in the telephone system are multiples of 125 µseconds.
Because of a failure to agree on an international standard for digital transmission, the systems used in Europe and North America are different. The North American standard is based on a 24-channel PCM system, wheras the European system is based on 30/32 channels. This system contains 30 speech channels, a synchronisation channel and a signalling channel, and the gross line bit rate of the system is 2.048 Mbps (32 x 64 Kbps). The system can be adapted for common channel signalling, providing 31 data channels and employing a single synchronisation channel. The following details refer to the European system.
The 30/32 channel system uses a frame and multiframe structure, with each frame consisting of 32 pulse channel time slots numbered 0-31. Slot 0 contains the Frame Alignment Word (FAW) and Frame Service Word (FSW). Slots 1-15 and 17-31 are used for digitised speech (channels 1-15 and 16-30 respectively). In each digitised speech channel, the first bit is used to signify the polarity of the sample, and the remaining bits represent the amplitude of the sample. The duration of each bit on a PCM system is 488 nanoseconds (ns). Each time slot is therefore 3.904 µseconds (8 bits x 488 ns). Each frame therefore occupies 125 milliseconds (32 x 3.904 mseconds).
In order for signalling information (dial pulses) for all 30 channels to be transmitted, the multiframe consists of 16 frames numbered 0-15. In frame 0, slot 16 contains the Multiframe Alignment Word (MFAW) and Multiframe Service Word (MFSW). In frames 1-15, slot 16 contains signalling information for two channels. The frame and multiframe structure are shown below. The duration of each multiframe is 2 milliseconds(125 µseconds x 16).
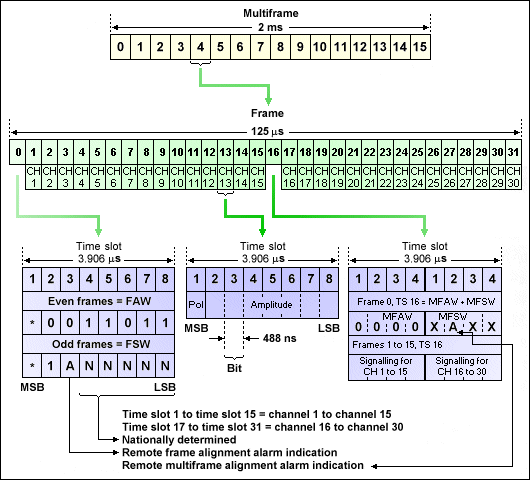
The frame and multiframe structures for a 30/32 channel PCM system