| Author: | |
| Website: | |
| Page title: | |
| URL: | |
| Published: | |
| Last revised: | |
| Accessed: |
If you have read any of the other articles in this section, you have probably already encountered functions. Those of you with experience of using programming languages such as C or C++ will be familiar with functions. Functions are the essential building blocks of all programming languages, including JavaScript. In some programming languages, such as Visual Basic, they are called subroutines or procedures.
A function is a block of code that carries out a specific task. In nearly all cases, we could write code to carry out that task without creating a function specifically for that purpose. So why do we need functions? Let's suppose we are writing a program that needs to carry out the same task multiple times. We could of course copy and paste the code from one part of our program to another, but that's not a particularly efficient way of writing a program. It increases the size and complexity of the program and makes it more difficult to read.
Then there's the question of how we deal with a situation in which the code is no longer doing everything we need it to do. Maybe the user has asked for the code's behaviour to be modified in some way, or for its functionality to be extended. It might even be that we find a better way to write the code, or wish to modify it in order to take advantage of advances in hardware. We are now faced with the task of finding all instances of that code within the program and making the necessary changes. This could be a somewhat tedious process, depending on just how many instances of the code we need to change. It also increases the possibility of errors creeping into our code.
It would be far better if we could write the code once and re-use it as and when necessary. Functions allow us to do just that - they let us write reusable code. When you need to carry out the same task many times in a program, creating a function allows you to write the code needed to implement the required functionality once, rather than writing the same code over and over again at different places in the program. This makes life much easier for the programmer. It also means that our programs will be more compact, and easier to maintain.
In order to make a function available to a program, we need to write a function declaration (sometimes called a function definition). A function declaration begins with the function keyword followed by the name of the function, which will enable us to invoke (or call) the function from wherever it is needed in our program. The name of the function is followed by a comma separated list of the parameters that are to be passed to the function, enclosed within parentheses.
Last but not least, it contains the code that will be executed when the function is invoked, enclosed within curly braces. The syntax for a function declaration looks like this:
function functionName(parameter1, parameter2, . . .) {
// code to be executed
}
The generally accepted convention for function names in JavaScript is that function names consisting of a single word are written in lowercase characters, while function names that consist of two or more words are written using camel case (or camel caps, or more formally medial capitals). This is where the first word appears in all lowercase letters, and the first letter of each subsequent word is capitalised, e.g.
function myFirstFunction()
Apart from that, you are free to call a function whatever you like, but there are one or two points you should bear in mind when naming a function. First and foremost, choose a name that accurately reflects what the function does. Suppose, for example, we want to create a function that takes a temperature in Fahrenheit as its input, and returns the temperature in Celsius. We might declare our function as follows:
function convertToCelsius(fahrenheit) {
return (5/9) * (fahrenheit-32);
}
The second thing to consider is that, because a function usually does something, the name should include a verb. In our example, the name convertToCelsius accurately describes what the function actually does. As a rule of thumb, if you create a meaningful function name that looks too long, it probably means you are putting too much functionality into a single function (or alternatively, being too verbose!).
The work to be undertaken out by the function is carried out by the program statements that appear within the function body (the code inside the curly braces). The convention used by most JavaScript programmers is to place the function body's opening curly brace on the same line as, and immediately following, the parenthesised parameter list. The function body’s code starts on the next line and is indented one level, and the closing curly brace sits on its own on the line below the code. This is not an absolute requirement, but if you choose to do things differently you should do so consistently.
We should probably point out at this point that not all functions need to be declared formally before we can use them in a JavaScript program. We can also create and use functions “on the fly” using function expressions. We will be looking at how this works later in this article.
Declaring a function our code does not execute the function. It simply names the function, lists the parameters it expects to receives, and specifies what the function will do when it is invoked. In order to actually use the function, we need to call it. A function call, as it is usually referred to, can be made from any point in the code if the function is declared within the global scope. The same is not true for block-level and nested functions (see below). The function call consists of the name of the function followed by a comma-separated list of the arguments the function expects to receive within parentheses:
//calling a function
function-name(parameter 1, parameter2, . . .);
Let’s say we want to create a function that raises one number to the power of another. It will take two arguments - the base (the number to be raised) and the exponent (the number that represents the power to which the base must be raised). We might do something like the following:
// the function declaration
function numToPower(a, b) {
return a ** b;
}
// the function is called by console.log
console.log(numToPower(2, 16)); // 65536
Note that even if the function does not take any parameters, we still need to include the parentheses in the function call. If we leave them out, then instead of executing the function, and receiving the function’s return value, the function call will receive the function itself. Suppose we create a function called sayHelloWorld() that simply returns the phrase “Hello World!”. No arguments are needed so the function declaration, and the subsequent function call might look something like the following:
// the function declaration
function sayHelloWorld() {
return "Hello, World!";
}
// the function is called by console.log()
console.log(sayHelloWorld()); // Hello, World!
This is what happens if we omit the parentheses from the function call:
// the function is called without parentheses
console.log(sayHelloWorld); // function sayHelloWorld()
Once the function has finished executing, it returns the value specified by the function’s return statement to the code that called the function. If no value is specified, or if the return statement is omitted altogether, the function returns a value of undefined. It also returns control of the program to the calling code. Program execution continues from the point in the program immediately following the function call.
Being able to call JavaScript functions in this way means that we can declare those functions in the head of an HTML document, or even in a separate JavaScript source file, and call them as and when needed from within the HTML code. This helps us to keep the HTML code itself clean and uncluttered. The code listing below creates an HTML page that allows a user to enter temperature values in either Fahrenheit or Celsius, and convert from one to the other. Here is the code:
<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8" />
<title>JavaScript Demo 30</title>
<style>
input { width: 3em; }
button { min-width: 6em; margin: 0.5em; }
.center { text-align: center; }
p { margin: 2em 0; }
.result {
user-select: none;
color: #000;
}
</style>
<script>
function fahrenheitToCelsius(fahrenheit) {
return (5/9) * (fahrenheit - 32);
}
function showResult() {
let input = document.getElementById("fahrenheit").value;
if(input == "") {
alert("You have not entered a temperature.");
}
else {
let fahrenheit = parseFloat(input);
if(isNaN(fahrenheit)) {
alert("Invalid input.");
clearAll();
}
else {
let celsius = fahrenheitToCelsius(fahrenheit);
document.getElementById("celsius").value = celsius;
}
}
return;
}
function clearAll() {
document.getElementById("fahrenheit").value = "";
document.getElementById("celsius").value = "";
}
</script>
</head>
<body>
<div class="center">
<h1>Convert Fahrenheit to Celsius</h1>
<p>Please enter a temperature in degrees Fahrenheit:</p>
<p>
<label>Temperature (°F): </label><input type="text" id="fahrenheit" />
<br><br>
<label>Temperature (°C): </label><input class="result" type="text" id="celsius" disabled />
</p>
<p>
<button onclick=" showResult()">Convert</button>
<br>
<button onclick="clearAll()">Clear</button>
</p>
</div>
</body>
</html>
Copy and paste this code into a new file in your HTML editor, save the file as javascript-demo-30.html, and open the file in a web browser. Enter a temperature value in the input field and click on the “Convert” button. Depending on what you entered, you should see something like this:
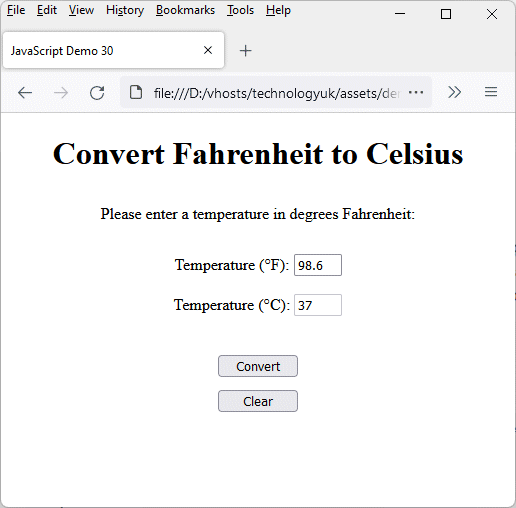
This web page allows a user to convert a temperature from Fahrenheit to Celsius
In this example, we have defined three functions - fahrenheitToCelsius(), showResult(), and clearAll(). The showResult() and clearAll() functions are both called from the body of the HTML code, when the “Convert” and “Clear” button are clicked, respectively. Neither of these functions requires any arguments. The fahrenheitToCelsius() function is called by the showResult() function, and takes a single argument, which should be a number. It is this function that carries out the actual conversion from Fahrenheit to Celsius.
Most of the code in the showResult() function is concerned with catching user errors. For example, if the user clicks on the “Convert” button before entering a number in the input box, a message is displayed that says “You have not entered a temperature.” and the showResult() function immediately returns. Similarly, if the user inputs something that is not a number, the message “Invalid input.” is displayed. The clearAll() function is then called, after which the showResult() function returns. What would happen if we were to remove the code that catches these errors? For example:
function showResult() {
let input = document.getElementById("fahrenheit").value;
let fahrenheit = parseFloat(input);
let celsius = fahrenheitToCelsius(fahrenheit);
document.getElementById("celsius").value = celsius;
return;
}
If we were to use the showResult() function as it appears above, the result would be the same whether the user failed to enter any input at all or entered some non-numeric term in the input field. The script still runs, but the result displayed in the output box will be NaN - a property of the global JavaScript object that represents the value “Not a Number”.
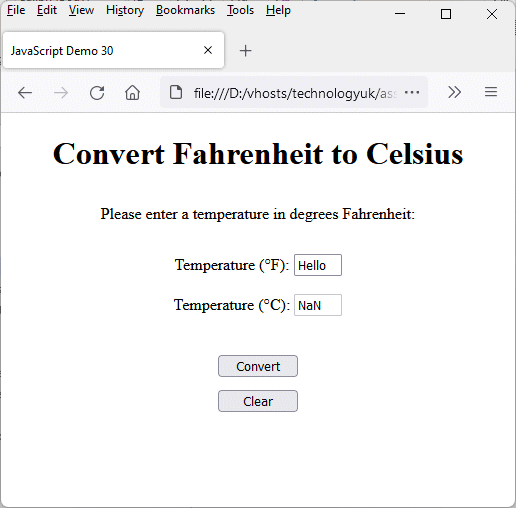
Missing or invalid input results in “NaN” being displayed in the output box
As we have mentioned previously, a function can have zero, one, or many parameters. We can think of them as placeholders for the arguments (values) that will be passed to the function when it is called. When we declare a function, the parameters appear in a comma-separated list immediately following the function name. Each parameter is essentially the name of a local variable that will be used by the function in some way. The values taken by those local variables will depend on the arguments supplied in the function call.
Arguments can be passed to functions by value or by reference, depending on the type of the argument. If we supply an argument with a primitive datatype (for example, a string, a number or a Boolean value) we are passing the argument by value. What does that mean exactly? Consider the following code:
function increment(a) {
a++;
return a;
}
console.log(increment(10)); // 11
In this example, we declare the increment() function with one parameter (a). The function’s only job is to increment the value of a by one, and return its new value. As you can see, when we pass a value of 10 to the function, it returns 11, which is exactly what you would expect. Within the function itself, the value of a is incremented using the increment operator. But what happens when, instead of simply passing a number to our function, we pass a variable? Consider this example:
function increment(a) {
a++;
return a;
}
let x = 10;
console.log(increment(x)); // 11
console.log(x); // 10
This time, we pass the variable x, which has a value of 10, as an argument. The initial value of a is therefore 10, but it is subsequently incremented by one, giving it a final value of 11. This is the value returned by increment(). As you can see, however, the value of variable x has not changed. That is because any variable with a primitive datatype that is passed to a function as a parameters is passed by value. Putting it another way, the function receives a copy of the variable, not the variable itself.
It is certainly possible for a function to change the value of an external variable. This could happen in a number of ways. We could, for example, pass x as an argument to the increment() function and assign the return value to x, like this:
function increment(a) {
a++;
return a;
}
let x = 10;
x = increment(x);
console.log(x); // 11
Alternatively, we could use the following approach (not recommended):
function increment() {
x++;
}
let x = 10;
increment();
console.log(x); // 11
In this example, the increment() function doesn’t accept any arguments. It simply increments the value of the external variable x directly. Quite apart from the fact that we don’t actually need a function here - we could achieve the same result by simply applying the increment operator to x - changing the value of external variables in this manner is considered bad practice, because it can lead to bugs in the code that are often difficult to trace. This is especially true for global variables that might be used by other parts of the program - one reason, in fact, why global variables should be avoided wherever possible.
If a variable we pass to a function as an argument is an object variable, the story is a little different, because an object variable is passed to a function by reference. The function is not getting a copy of the object, rather it is getting a reference to the object itself. This means that if the function changes the value of one of the object’s properties, the change is reflected in the object itself. For example:
function changeClass(name, newClass) {
name._class = newClass;
return;
}
const blueWhale = {
kingdom: "Animalia",
phylum: "Chordata",
_class: "Chondrichthyes",
order: "Artiodactyla",
family: "Balaenopteridae",
genus: "Balaenoptera",
species: "B. musculus"
};
console.log(blueWhale._class);
changeClass(blueWhale, "Mammalia");
console.log(blueWhale._class);
When we start looking at JavaScript objects in more detail, we will see that a function that sets or changes the value of one of the object’s properties should really be defined within the object itself as one of the object’s methods. We have used the example above merely to demonstrate that an object is passed to a function by reference, the so the function can make changes to the object itself.
Some programming languages are fairly strict about the number and type of the arguments passed to a function. In C++, for example, if there are either too few or too many arguments, an error will occur when you try to compile the program. Similarly, if one or more of the arguments supplied to a function have a datatype that does not match the datatype specified for the corresponding parameter in the function declaration, the C++ compiler will complain.
JavaScript is a lot more relaxed when it comes to function parameters. If we supply too many arguments to a function, it will simply ignore the extra values, as in this example:
function product(a, b) {
return a * b;
}
console.log(product(3, 5, 7, 9)); // 15
If on the other hand we supply too few arguments, JavaScript automatically assigns the value undefined to any missing parameters. This can produce some unexpected results, but it won’t bring your script crashing down in flames. For example:
function product(a, b) {
return a * b;
}
console.log(product(3)); // NaN
In the example above, JavaScript has assigned the value undefined to the second parameter (b), so the calculation it carries out is 3 * undefined, which results in NaN (Not a Number).
What happens if we pass an argument of the wrong type to a JavaScript function? JavaScript differs from programming languages like C and C++ in that we do not have to declare a function parameter datatype. JavaScript infers the datatype from the argument passed to it. We can pass any kind of datatype to a JavaScript function, and it will still execute the code in the function body, although once again the result may not be what we were expecting. For example, consider this example:
function concat(a, b) {
return a + b;
}
console.log(concat("Have a ", "nice day!")); // Have a nice day!
console.log(concat(3, 5)); // 8
console.log(concat("A number: ", 2.5)); // A number: 2.5
The first time we call concat(), we supply two string literals as arguments and JavaScript makes the perfectly reasonable assumption that we require the “+” in our function definition to act as the string concatenation operator. The second time we call concat(), we supply two numeric variables, and JavaScript assumes that we want to add the values together - again, a perfectly reasonable assumption.
The final invocation of concat() could be said to be somewhat ambiguous, because we pass a string as the first argument and a numeric value (without quotes) as the second. However, since it would not make sense to try and add a string and a number together, JavaScript does the next best thing and converts the numeric value to a string, which is after all what the function is actually intended to do (the clue is in the function’s name).
These examples highlight the flexibility of JavaScript functions. We are not bound by the strict rules that some languages impose when it comes to typed parameters, which means that we can write functions that do different things, depending on what kind of arguments are passed to them. On the other hand, because there is always the potential for unexpected side effects, we need to be somewhat more diligent when writing and using functions, because if we accidentally pass too many arguments, too few arguments, or the wrong kind of arguments to a function, nobody is going to tell us.
Starting with ECMAScript 2015, which was the sixth edition of the JavaScript language specification, two new kinds of parameter were introduced for use with JavaScript functions - default parameters and rest parameters. We have already seen that if a function receives fewer arguments than are specified in its parameter list, the local variables representing the missing arguments will be assigned a value of undefined. We can now circumvent this behaviour by assigning a default value to one or more parameters (this was not allowed prior to the adoption of ECMAScript 2015). Consider the following example:
function numToPower(a, b=2) {
return a ** b;
}
console.log(numToPower(10)); // 100
console.log(numToPower(10, 3)); // 1000
We saw the numToPower() function earlier. As previously, it takes two numerical arguments and raises the first to the power of the second. In this example, a default value of 2 has been supplied for the second parameter (the exponent). If no second argument is supplied, the first argument is raised to the power of 2 (in other words, squared). In order to achieve the same end result prior to ECMAScript 2015, we could have done something like this:
function numToPower(a, b) {
if(b === undefined) {
b = 2;
}
return a ** b;
}
console.log(numToPower(10)); // 100
console.log(numToPower(10, 3)); // 1000
There is, in fact, nothing preventing us from writing a function that does different things depending on the number and type of the parameters it receives. Bear in mind, however, that this is a departure from the guiding principle that a function should carry out one task and one task only. If a function is doing too many different things, it should probably be broken down into a number of smaller functions.
The idea behind rest parameters is that they allow us to pass multiple arguments to a JavaScript function without having to specify individual parameters for those arguments, and without having to specify the number of arguments expected. This is very useful when we want to carry out the same operation on multiple arguments without knowing up front how many arguments we are dealing with. Consider the following example:
function multiply(multiplier, ...args) {
return args.map(x => multiplier * x);
}
arr2 = multiply(4, 1, 2, 3, 4);
console.log(arr2); // Array(4) [ 4, 8, 12, 16 ]
const arr1 = [1, 2, 3, 4];
arr3 = multiply(4, ...arr1);
console.log(arr3); // Array(4) [ 4, 8, 12, 16 ]
Note the use of the JavaScript spread operator (…), which consists of three U+002E period (or full stop) characters. The first time it is used in our example is in the function declaration itself, where its purpose is to tell the JavaScript interpreter that the second parameter is a rest parameter. This causes all arguments that follow the first argument to be treated like a standard JavaScript array (note that only the last parameter in a function definition can be a rest parameter).
We use the JavaScript spread operator again when we call the multiply() function a second time. This time, the second argument is an array, whereas multiply() is expecting a comma-separated list of numeric values as the argument corresponding to its rest parameter. In this context, therefore, the purpose of the spread operator is to convert the array into a comma-separated list of values, which multiply() then converts back into an array!
As we have previously mentioned, all JavaScript functions return a value. If no return statement is used, or if the return statement is used on its own without specifying the value to be returned, the value returned is undefined. The statements within a function will execute in the order in which they appear. If no return statement is encountered, the function will terminate when all of its statements have been executed. If a return statement is encountered, the function will terminate immediately. In either case, once the function terminates, program execution will continue from the point in the program from which the function was called.
As we have already seen, a function typically takes some number of arguments as its input, computes a value based on those arguments, and then returns that value to whatever part of the program called the function. In this kind of scenario, a return statement is always required, and the value to be returned must immediately follow the return statement. One word of warning in this respect: if the value to be returned is the result of evaluating a complex expression, don’t fall into the trap of putting that expression on its own line after the return statement. JavaScript will automatically assume a semicolon after the return keyword. Consider the following example:
function addFourNumbers(input01, input02, input03, input04) {
return
(input01 + input02 + input03 + input04);
}
let result = addFourNumbers(9, 15, 27, 32);
console.log(result); // undefined
As you can see, the addFourNumbers() function returns the value undefined rather than the value you would expect to see (83). You will probably also see the JavaScript warning message “unreachable code after return statement”. The expression whose value is to be returned should always appear on the same line as, and immediately following, the return statement:
function addFourNumbers(input01, input02, input03, input04) {
return (input01 + input02 + input03 + input04);
}
let result = addFourNumbers(9, 15, 27, 32);
console.log(result); // 83
This time, the addFourNumbers() function returns the correct value. Generally speaking, it is hardly ever necessary to wrap a return statement over multiple lines, but if you really must do this, start the expression to be evaluated on the same line as, and immediately following, the return statement. For example:
function addFourNumbers(input01, input02, input03, input04) {
return (
input01 + input02 + input03 + input04
);
}
let result = addFourNumbers(9, 15, 27, 32);
console.log(result); // 83
In this case, simply placing the opening parenthesis of the expression to be evaluated on the same line as the return keyword has the desired effect, and the addFourNumbers() function returns the correct value.
We can use multiple return statements in a function in order to return different values, depending on the outcome of evaluating one or more conditional statements. Suppose, for example, we wanted to compare the value of two variables, a and b. In this scenario, there are three possible outcomes: a is greater than b, b is greater than a, or a and b have the same value. The following code demonstrates how we might implement a function that returns different values depending on which of these outcomes occurs:
function compare(a, b) {
if (a > b) {
return 1;
}
else if (a < b) {
return -1;
}
return 0;
}
let x = 10, y = 5;
console.log(compare(x, y)); // 1
x = 8, y = 16;
console.log(compare(x, y)); // -1
x = 21, y = 21;
console.log(compare(x, y)); // 0
We have seen that function parameters are essentially the names of local variables used within the function, and that the value taken by these variables will depend on the value of the arguments received by the function. If we declare additional variables within the function body, they too are local variables. This means that only code inside the function can access them; they are invisible to code outside the function. It also means that variables with the same name can be used in different functions.
But what happens if we declare a local variable within a function that has the same name as some external variable to which the function has access? Consider the following example:
let message = "Hello, Susan!"
function sayHello(name) {
let message = "Hello, " + name + "!";
return message;
}
console.log(sayHello("Christopher")); // Hello, Christopher!
console.log(message); // Hello, Susan!
When the sayHello() function sets the value of the locally declared variable message, the value of the external message variable is unchanged. When a variable declared inside a function has the same name as an external variable, JavaScript assumes that any use of that variable name inside the function refers to the local variable and not the external variable. Of course, we can access an external variable, and even change its value, if there is no local variable with the same name. The following code is almost identical to the example we just saw, but produces a different outcome:
let message = "Hello, Susan!"
function sayHello(name) {
message = "Hello, " + name + "!";
return message;
}
console.log(sayHello("Christopher")); // Hello, Christopher!
console.log(message); // Hello, Christopher!
As you probably noticed, in this example we have omitted the let keyword from the first line of code in the function body. Consequently, the variable name message is assumed by JavaScript to refer to the external variable of that name. A word of warning here, however. Suppose we omit the let keyword, but haven’t declared an external variable called message. Let’s see what happens:
function sayHello(name) {
message = "Hello, " + name + "!";
return message;
}
console.log(sayHello("Christopher")); // Hello, Christopher!
console.log(message); // Hello, Christopher!
This code produces the same result as before, but how can that be if message is a local variable? The reason is that in JavaScript, variables can be declared and initialised without using the let, var or const keywords, although a value must immediately be assigned to a variable declared in this way. What you need to be aware of, however, is that any variable declared without the let, var or const keywords automatically becomes a global variable, regardless of where it is declared. Declaring a variable in this way can therefore have unforeseen consequences, and is generally considered bad practice. The following code is better:
function sayHello(name) {
let message = "Hello, " + name + "!";
return message;
}
console.log(sayHello("Christopher")); // Hello, Christopher!
console.log(message);
// Uncaught ReferenceError: message is not defined
Using the let keyword to declare the message variable inside the sayHello() function means that it is indeed a local variable, and can only be seen by the code inside the function body. Any reference to that variable name outside the function body results in an error message. It is also worth noting that a local function variable is created when the function is called, and is destroyed once the function has finished executing. This makes for efficient use of memory, since function variables only need to be stored while they are actually in use.
The arguments object is an array like object that is created when a function is called. It is essentially a container that holds the values of all of the arguments passed to the currently executing function. It allows you to access all of the arguments passed to a function using an index, as shown here:
function myFunc(a, b, c, d) {
console.log(arguments[0]); // 1
console.log(arguments[1]); // 2
console.log(arguments[2]); // 3
console.log(arguments[3]); // 4
}
myFunc(1, 2, 3, 4);
In fact, we can even leave the function’s formal parameter list empty and still access any arguments passed to the function using the arguments object:
function myFunc() {
console.log(arguments[0]); // 1
console.log(arguments[1]); // 2
console.log(arguments[2]); // 3
console.log(arguments[3]); // 4
}
myFunc(1, 2, 3, 4);
Like an array, the arguments object has a length property which holds the number of arguments passed to the function (although it doesn’t support array methods). This allows us to pass multiple arguments to a JavaScript function without specifying any formal parameters or the number of arguments expected. This makes it possible to carry out the same operation on multiple arguments without knowing in advance how many arguments we are dealing with. Consider the following example:
function multiply(multiplier) {
const arr = [];
for (i = 1; i < arguments.length; i++) {
arr[i-1] = multiplier * arguments[i];
}
return arr;
}
console.log(multiply(4, 1, 2, 3, 4)); // Array(4) [ 4, 8, 12, 16 ]
The multiply() function obtains the total number of arguments actually supplied to it using the arguments.length property. It then iterates through the arguments (starting with the second argument) using a for loop in order to create an array, which is then returned. This function should look familiar to you because we have already seen a version of the multiply() function that does exactly the same thing using rest parameters to process multiple arguments.
Using rest parameters has some advantages, and is generally preferred. For example, rest parameters are array instances, which means that we can apply array methods to them as we have seen. When we use rest parameters, the ...restParam array contains only those arguments that do not correspond to any other formal parameters, whereas the arguments object will include any arguments supplied against named parameters together with the values in the ...restParam array:
function someFunc(arg1, arg2, ...args) {
console.log(args); // Array(3) [ 3, 4, 5 ]
console.log(arguments[0]); // 1
console.log(arguments[1]); // 2
console.log(arguments[2]); // 3
console.log(arguments[3]); // 4
console.log(arguments[4]); // 5
}
someFunc(1, 2, 3, 4, 5);
In order to be able to use a function, that function must be visible in the scope from which it is called. What does that mean exactly? The answer is not quite as straightforward as we would hope, thanks largely to significant changes made to the ECMAScript specification over the years in this respect. Prior to ECMAScript 2015 (also known as ECMAScript 6 or just ES6), JavaScript had just two kinds of scope - function scope and global scope.
The ECMAScript standards up to and including ES3 stated that functions should not be declared inside a block statement. Block statements are typically used with JavaScript control structures such as if . . . else and for statements. Technically, therefore, the following code should have generated a syntax error:
if (true) {
function myFunction() {
// function body statements
}
}
Unfortunately - or fortunately, depending on how you look at it - most browsers would execute the code without generating a syntax error. ES5 introduced a “strict mode” intended to force browsers to generate an error if a function was declared inside a block. There are two problems with this approach, however. The first problem is that developers can choose whether or not to use strict mode, and many simply don’t bother. The second problem is that, although strict mode is now supported and handled in the same way by all major browsers, this was not always the case. Indeed, some older browsers effectively ignore strict mode altogether.
Attempts to prevent the declaration of functions inside blocks appear to have been abandoned as of ES6, with functions declared inside a block (known as block-level functions) being permitted. In strict mode, however, block-level functions have block scope only. They are “hoisted” to the top of the block in which they are declared, which means that a function call can be made from anywhere inside the block even if it appears before the function declaration, but a block-level function is not available to code outside of the block in strict mode. For example:
'use strict';
if (true) {
console.log(myFunction()); // true
function myFunction() {
return true;
}
}
console.log(myFunction());
// Uncaught ReferenceError: myFunction is not defined
If strict mode is not used, all functions declared in the global scope are processed before any code is executed, so they are effectively “hoisted” to the top of the script, regardless of where they have been declared, and can be called from anywhere in the script. The behaviour of block-level functions is not so easily determined. In the above example, the myFunction() function is only created if the if statement evaluates to true, which of course it does. Suppose that instead we do this:
if (true) {
function myFunction() {
return true;
}
}
console.log(myFunction()); // true
if (false) {
function anotherFunction() {
return false;
}
}
console.log(anotherFunction());
// Uncaught TypeError: anotherFunction is not a function
There are two points to consider here. First of all, the block-level function myFunction() will always be processed because the if statement within which it is declared always evaluates to true, whereas the block-level function anotherFunction() will never be processed because its if statement always evaluates to false. The second thing to consider is that, even though we are not using strict mode, the myFunction() function is only available after the if statement within which it is declared has been evaluated. The following code won’t work:
console.log(myFunction());
// Uncaught TypeError: myFunction is not a function
if (true) {
function myFunction() {
return true;
}
}
The general consensus seems to be that, in non-strict mode at least, declaring a function inside a block, even though it is permitted, can lead to unforeseen side effects, and there would appear to be little benefit to doing so. Our recommendation would therefore be to avoid using block-level functions (an alternative would be to use function expressions, which we’ll be looking at next).
A function can be assigned to a JavaScript variable using a function expression, after which that variable can be used as a function. A function expression is similar to a function declaration, except that the function keyword is used to define the function inside an expression, and no function name is required. For example:
const square = function(x) { return x ** 2; };
console.log(square(8)); // 64
If the function name is omitted, as it has been in the above example, the function is said to be anonymous. A function name can be provided, but will only have local scope (it is only visible to the function itself). We could provide a function name if we wanted the function to be able to refer to itself (see Recursion below), or so that we could identify the function during debugging.
Unlike functions that are defined using a function declaration, function expressions are not hoisted, and cannot be used until they have been defined. As you can see from the above example, when the function expression is assigned to a variable, the function is called using the variable name followed by parentheses containing the function’s arguments. The function code is then executed immediately.
Function expressions are more flexible than formal function declarations because they allow us to write inline function code. This is especially useful if you are writing function code that will only be used once. The ability to create anonymous functions means that we can avoid cluttering up the global namespace. The trade-off is that function expressions are not always so easy to read.
Function expressions are convenient when you wish to pass a function as an argument to another function. The function expression is assigned to a variable, which can then be passed to a function in the same way as any other variable. For example:
const square = function(num) { return num ** 2; };
const root = function(num) { return num ** (1/2); };
function displayResult(x, func) {
return "The result of the calculation is " + func(x);
}
console.log(displayResult(9, square));
// The result of the calculation is 81
console.log(displayResult(9, root));
// The result of the calculation is 3
You don’t even have to assign the function expression to a variable - you can pass it directly to a function as one of its arguments, as the following example demonstrates:
function displayResult(x, func) {
return "The result of the calculation is " + func();
}
console.log(displayResult(9, function () {
return displayResult.arguments[0] ** 2;
})); // The result of the calculation is 81
console.log(displayResult(9, function () {
return displayResult.arguments[0] ** (1/2);
})); // The result of the calculation is 3
Before we proceed, we should also bring your attention to the relatively recent addition of a more compact syntax for writing functions in JavaScript using arrow notation. Arrow function expressions are always anonymous. An arrow function expression does not have its own binding to this, or its own arguments object. The new syntax was introduced by ECMAScript 2015 (ES6), and enables simple function expressions to be written in a less verbose way. Compare the following:
const square = function(x) { return x ** 2; };
console.log(square(8)); // 64
with this:
const square = x => x ** 2;
console.log(square(8)); // 64
Both function expressions do exactly the same thing, but using arrow notation has allowed us to omit the function and return keywords, as well as the parentheses around the function parameter and the braces surrounding the function’s return statement. An arrow (=>) separates the parameter from the return statement.
Note that we can only dispense with the parentheses for the function parameter list if there is exactly one function parameter. If there are no function parameters, or if there are multiple function parameters, parentheses are still required. For example:
const greeting = () => "Hello!";
console.log(greeting()); // Hello!
const mul = (x, y) => x * y;
console.log(mul(5, 7)); // 35
Similarly, we can only dispose of the braces around the function body if it simply returns an expression. If the body has multiple statements, the braces are required, and so is the return keyword. For example:
const countChars = inputString => {
strLength = inputString.length;
return "The number of characters found is " + strLength;
};
console.log(countChars("The boy stood on the burning deck"));
// The number of characters found is 33
Whether or not to use arrow notation is a decision for the programmer (or programming team). It does not replace the standard syntax, merely offers an alternative to it. It offers brevity, possibly at the cost of readability. It seems to work well for simple one-line function expressions that take one or two arguments and return an expression based on those arguments. For more complex function expressions, we have to decide whether the benefits of having to type a few characters less outweigh the possible loss of readability.
JavaScript allows us to nest one function inside another function. The inner function can only be accessed by code residing within the outer function; it cannot be accessed by code that is external to the outer function. Furthermore, the outer function does not have access to the inner function’s local variables. The inner function, on the other hand, does have access to all of the outer function’s parameters and local variables. Nesting one function inside another in this way creates something called a closure.
According to an MDN Web Docs article on closures:
“In JavaScript, closures are created every time a function is created, at function creation time . . . . . A closure is the combination of a function and the lexical environment within which that function was declared. This environment consists of any local variables that were in-scope at the time the closure was created.”
A comprehensive technical explanation of what closures are and how they work is beyond the scope of this article. We will however attempt to explain some of the basic principles of closures from a developer perspective, and will provide some concrete examples to illustrate how they might be used. Those intending to use closures extensively in their work should probably undertake a more in-depth study because, while there are unquestionably a number of benefits to using closures, there are also some pitfalls to look out for.
JavaScript was the first mainstream programming language to successfully implement the concept of closure, which is also called lexical or static scoping. In fact, the idea of scope is central to the concept of closures. There are three main types of scope in JavaScript - global scope, block scope, and function scope.
Global variables can be accessed from anywhere, whereas variables declared inside a code block or a function can only be accessed by code residing within that code block or function. The exceptions to this rule are variables declared with the var keyword, which are visible outside the block in which they are declared - one good reason not to use var to declare variables (or anything else).
The lexical environment for a function created in the global scope includes all global variables (global variables automatically become members of the JavaScript global object). Let’s say we want to create a function to update the value of a simple counter variable. The easiest way to do this would be to declare the counter variable as a global variable. Then we could do something like this:
let count = 0;
function incrementCount() {
count += 1;
}
incrementCount();
console.log(count); // 1
incrementCount();
console.log(count); // 2
incrementCount();
console.log(count); // 3
This works because the global variable count belongs to the (global) lexical environment within which the function incrementCount() is created. So far, this is fairly intuitive, because we already know that global variables are accessible from any part of a program. We also know, however, that the use of global variables should be avoided because it clutters up the global namespace, and because it is too easy for one script to inadvertently overwrite a global variable being used by another script.
Declaring our counter variable as a local variable inside incrementCount(), even if we use var instead of let, will hide it from other parts of the program because the scope of the variable is limited to that function, as we have already seen. The problem with this scenario is that the count variable is created each time incrementCount() is called, and discarded each time it returns - its value therefore never becomes greater than one:
function incrementCount() {
let count;
if(count === undefined) {
count = 0;
}
count += 1;
return count;
}
console.log(incrementCount()); // 1
console.log(incrementCount()); // 1
console.log(incrementCount()); // 1
When a function is called, memory is allocated for the function call on something called the call stack. JavaScript also creates an execution context - essentially, the environment in which the function is evaluated and executed, and an activation object that holds the arguments supplied to the function, together with any variables and functions declared inside the function.
Once the function has carried out its designated task and returned a value, it is removed from the call stack, its execution context ceases to exist, and the activation object is no longer accessible (the activation object may persist in memory until it is “garbage collected”, but is no longer visible to any part of the program).
In many cases, this is exactly what we want to happen, but it’s obviously not what we want to happen with our incrementCount() function. We are therefore faced with a dilemma. How do we write a function that does not re-create the counter variable it is intended to increment each time it is called? This is where nested functions come to the rescue.
Function scope is like block scope. A block of code inside another block of code has access to any variables declared within the scope of the outer block. Similarly, an inner (nested) function has access to any variables declared within the scope of the outer function because it has access to the outer function’s activation object, which as we have already seen holds both the arguments supplied to the function and any variables declared within it. The outer function, on the other hand, does not have access to the variables declared within the inner function.
The question you’re probably asking at this point is: “How does that help us with our counter problem?” We’re getting to that. The important thing to grasp here is that a nested function forms a closure that gives it access to all of the outer function’s variables. The nested function will continue to have access to those variables until it returns.
Normally, when a function returns, any function nested within it will cease to exist. But what happens if the function’s return value is the nested function itself? Thanks to closure, when an outer function returns an inner function, the inner function still has access to all of the outer function’s variables. The memory they occupy cannot be garbage collected because the inner function maintains an active reference to that memory. They will therefore persist in memory, and be available to the inner function until the inner function returns.
Probably the best way to demonstrate the significance of all this is to look at a concrete example. In order to do so we’ll re-think our incrementCount() function. Consider this code:
const incrementCount = (function () {
let count = 0;
return function () {
count += 1; return count;
}
})();
console.log(incrementCount()); // 1
console.log(incrementCount()); // 2
console.log(incrementCount()); // 3
As well as maintaining access to the count variable using a closure, we also need to be able to initialise the count variable once only. In order to ensure that this happens, we have used an Immediately Invoked Function Expression (IIFE) that executes once only, as soon as the function expression is declared. The basic syntax for an IFFE - sometimes referred to as the IFFE design pattern - is as follows:
(function() {
// statements
})();
So how exactly does this function expression work? Essentially, what we have is two anonymous functions, one nested inside the other. Because we have used the IIFE design pattern, the outer function executes immediately, initialising the count variable and returning the inner function, which is assigned to incrementCount.
Because the inner function forms a closure, it retains access to the outer function’s count variable even though the outer function has returned. As a consequence, incrementCount becomes a function that has access to the outer function’s count variable, and will increment that variable’s value each time it is invoked.
We could also create our incrementCount function using arrow notation, which involves writing less code at the cost of being somewhat (in our view) less readable. Here is the code:
const incrementCount = (() => {
let count = 0;
return () => count += 1;
})();
console.log(incrementCount());
console.log(incrementCount());
console.log(incrementCount());
Closures are not limited to a single level of nesting. A function can be nested within a function that is nested inside another function . . . and so on. There is no official limit to the level of nesting possible, although since each instance of a function must manage its own scope and closure, performance may be negatively impacted in terms of processing speed and memory consumption if there are multiple levels of nesting. The generally accepted principle is that nested functions should only be used where necessary, i.e., for a task that cannot easily be undertaken using other means.
If a function is deeply nested, then it has access to the scope of each function above it, together with the global scope - a kind of scope hierarchy, so to speak, which we call the scope chain. A function at any level in the scope chain has access to all of the function scopes above it, but cannot access any of the function scopes below it. The following code demonstrates the principle:
function A(x) {
function B(y) {v
function C(z) {v
console.log(x + y + z);
}
C("the burning deck.");
}
B("stood on ");
}
A("The boy "); // The boy stood on the burning deck.
Closures are useful when we want to create globally accessible functions that have access to private functions and variables. As such they enable us to realise some of the benefits of object-oriented programming languages such as C++ and Java in terms of data hiding and encapsulation.
A function that can call itself is said to be recursive. Recursive functions can be used to process things like lists, stacks and queues. They can be used in any situation, in fact, where we need to process a large number of data items one by one, carrying out the same operation on each, until we encounter some exit condition.
When writing a recursive function, it is very important to ensure that there is an exit condition, and that that exit condition will be encountered at some point. Otherwise, we risk creating an infinite loop that will eventually cause our program to crash because it has run out of stack space. This is a very real danger because of the way that function calls are handled in JavaScript (and other languages) - but more about that later.
Let’s look at a concrete example of a recursive function - in this instance, a function that computes factorials. The factorial of a positive integer is the product of all positive integers that are less than or equal to that integer. The factorial of 5 - written as 5! - would be calculated as 1 × 2 × 3 × 4 × 5 = 120 . The following code creates a recursive function that can calculate the factorial of any positive integer (up to about 170 - after that the result is a number too large for JavaScript to display and it simply returns infinity):
function factorial(n) {
if (n <= 1) {
return 1;
}
return (n * factorial(n - 1));
}
console.log(factorial(7)); // 5040
console.log(factorial(170)); // 7.257415615307994e+306
console.log(factorial(171)); // infinity
The exit condition (n <= 1) will eventually be met because each recursive call to factorial reduces the value of n by one. Could we write this function using a loop? Consider the following code:
const factorial = function(n) {
let result = 1;
for(let i = 1; i <= n; i++) {
result *= i;
}
return result;
}
console.log(factorial(7)); // 5040
console.log(factorial(170)); // 7.257415615307994e+306
console.log(factorial(171)); // infinity
As you can see, we can implement the factorial() function quite easily using a simple loop. The code is not quite so compact and elegant as the recursive version, but is perhaps easier to understand. More importantly, this non-recursive version of the factorial() function executes almost eight times faster than the recursive version. In many cases this performance difference would not even be noticeable (both functions execute in just a tiny fraction of a millisecond), but it could become significant in processor-intensive environments.
The main obstacle to good performance for recursive functions is that fact that, each time the function calls itself, memory is allocated for a new instance of the function on the call stack. In addition, a new execution context and activation object are created in heap memory. All of this takes a considerable amount of processing time. It also ties up a significant amount of memory, which is only released when the last call to the recursive function returns.
For simple iterative tasks such as list processing or array processing, functions that use loops will generally perform far better than recursive functions, even though the code used to implement them may not look as elegant. Recursive functions really come into their own when we have to deal with non-linear data structures.
Data is often stored in a hierarchical structure that resembles an upside-down tree. Indeed, this type of data structure is invariably referred to as a tree in computing circles. Because a tree is non-linear, any attempt to traverse it using a loop would present challenges, to say the least. One of the classic use cases for recursion is traversing the HTML Document Object Model (DOM).
The W3C DOM is an object model and programming interface for web documents. It represents a HTML document as a tree-like structure consisting of a hierarchy of nodes, each of which represents a document element. Some nodes can have child nodes of various kinds, while others are leaf nodes. The root node of an HTML document tree is the Document node, which can contain various HTML elements, each of which can contain other HTML elements, comments, and text.
Being able to traverse the DOM structure is essential if you want to be able to dynamically create or manipulate web documents using JavaScript. The code below, written by Douglas Crockford, implements a recursive function for traversing the DOM, together with an example of how it might be used. For those interested, you can watch Douglas Crockford’s 2006 lecture “An Inconvenient API - The Theory of the DOM” here.
function walkTheDOM(node, func) {
func(node);
node = node.firstChild;
while (node) {
walkTheDOM(node, func);v
node = node.nextSibling;
}
}
// Example usage: Process all Text nodes on the page
walkTheDOM(document.body, function (node) {
if (node.nodeType === 3) { // Is it a Text node?
var text = node.data.trim();
if (text.length > 0) { // Does it have non white-space text content?
// process text
}
}
});