| Author: | |
| Website: | |
| Page title: | |
| URL: | |
| Published: | |
| Last revised: | |
| Accessed: |
A JavaScript string consists of a sequence of zero or more UTF-16 characters enclosed between double quotes, single quotes or backticks. The following variable declarations all create string variables with the same value:
let str1 = "Hello World!";
let str2 = 'Hello World!';
let str3 = `Hello World!`;
In this article, we're going to be looking at how JavaScript manages strings, and in particular at the string methods available in JavaScript. Which immediately raises an obvious question - how can a string, which in JavaScript is a primitive datatype and not an object, have methods? Methods, after all, are usually only associated with objects. A JavaScript method is essentially a property of an object that contains a function definition.
JavaScript has seven primitive data types (i.e. data types that are not objects and do not have methods: string, number, bigint, boolean, null, undefined, and symbol, which we discuss in some detail in the article "JavaScript basics" in this section.
We stated in that article that JavaScript primitives are immutable, because their values cannot be changed. When a script appears to change the value of a string variable, it is in fact allocating a new block of memory to hold the new value, and associating the variable name with the address of that block of memory. We now want to introduce a new concept - that of wrapper objects for primitive data types.
Of the seven primitive data types, all but two (null and undefined) have an equivalent object that "wraps around" them. These objects are listed below. Note that each object has the same name as the primitive for which it is the wrapper, except that the name of the primitive datatype is written in all lowercase, whereas the first letter of the object name is capitalised:
The primitive datatype we are interested in here is the string datatype, for which the object that acts as a "wrapper" is the String object. We can think of a wrapper as a kind of "utility belt" that JavaScript temporarily provides for a primitive data type when called upon to do so, and which contains all of the tools necessary to allow the primitive datatype to behave like an object. Consider the following code snippet:
let strLength = 0;
let myString = "Hello World!";
strLength = mystring.length;
The first two statements declare the variables strLength and myString, and assign them the values 0 and "Hello World!" respectively. The last statement retrieves the value of the String object's length property for myString and assigns the result to strLength. So how does that work?
The JavaScript interpreter detects that we wish to access the length property of a string primitive, and creates a String wrapper object for the string primitive. Once this has been achieved, the value of the String object's length property can be retrieved and assigned to the strLength variable. The wrapper object is then discarded and its memory is freed.
We can take advantage of the wrapper created for a primitive string variable in order to access the properties of, and call on the methods available to, the String object. Remember however, that a primitive variable is immutable; a method that appears to change the string in some way is not changing the original string value; it is creating a new string value and assigning the variable name to the address of the new string value.
There is however another possibility which we have not yet mentioned, which is that we can create a new instance of the String object using the object's constructor function. Consider the following code snippet:
let myString1 = "Hello World!";
let myString2 = new String("Hello World!");
We now have two string variables containing the text "Hello World!". We can call all of the methods available to the String object on either of these variables. The difference is that myString1 is a string primitive that can access the methods of the String object, whereas myString2 is an object in its own right, with methods identical to those of the String object. The JavaScript typeof operator will return different results for these two variables:
typeof myString1; // returns "string"
typeof myString2; // returns "object"
Furthermore, despite the fact that both variables contain exactly the same text, JavaScript does not consider them to be equal:
myString1 == myString2; // returns "false"
Generally speaking, you should avoid explicitly creating primitive object wrappers using the new keyword. There is no compelling reason to do so, and it can lead to misunderstandings when you or another developer needs to revisit your code at a later date in order to maintain or update it.
Before we proceed it is worth mentioning that strings declared using backticks (as opposed to double or single quotes) are known as template literals. The concept of template literals (originally called template strings) was introduced with the ECMAScript 2015 (ES6) standard. At first glance, a template string is the same as a standard string literal, but it's not. A template string allows us to do all sorts of interesting things, like plugging JavaScript variables directly into a string without having to use concatenation. We'll be looking at template strings in more detail later.
Thanks to the concept of wrappers, which we described earlier, we can use all of the methods available to the JavaScript String object for primitive string variables. Wrappers also give us access to the String object's properties for those variables. There are three properties associated with a string that you should be aware of:
We'll deal with each of these properties in turn, starting with length, which is a property you will often need access to if you are going to be creating scripts of any consequence. The length property is read-only; it cannot be changed programmatically, and its value is determined by how many UTF-16 code units the string contains. For example:
let str = "Hello World!";
let strLen = str.length;
// the value of strLen is 12
We emphasised the term code units for a reason. Most of the strings that you use in your scripts will consist of characters that consist of a single UTF-16 code unit. Some rarely-used special characters, however, require two UTF-16 code units. It may well be the case that you will never actually use one of these characters in your scripts, but if you do, you should be aware that the value of the length property will reflect the number of code units in the string rather than the number of characters that make up the string.
The next property we want to look at is the constructor property which, like length, is a read-only property. An object's constructor property contains a reference to the constructor function that created that object. It is a reference to the function itself, not a string containing the function's name. For example:
let str = "Hello World!";
let strCstr = str.constructor;
// the value of strCstr is: function String() { [native code] }
Now you know this, you can forget about it for the time being. It is unlikely that you will ever need to access a string object's constructor directly in your scripts.
The last property we'll look at is the prototype property. This property allows you to add properties and methods to an object. To demonstrate this, we're going to add a method to the String object that reverses the order of the calling string. Before we do that, however, let's see how we might reverse the order of a string without calling on the prototype property. Consider the following code:
function reverseString (str) {
let strRev = "";
for (i = str.length - 1; i >= 0; i--) {
strRev += str[i];
}
return strRev;
}
let str = "Hello World!";
str = reverseString(str);
// the value of str is "!dlroW olleH"
It would certainly be convenient if the String object actually had a method that would reverse the order of the characters in any string it was called on, which at the moment, it doesn't. Suppose we could add our reverseString() function to the String object's methods? Actually, using the String object's prototype property, we can. We just need to make a minor adjustment to our function:
function reverseString (str) {
if (!str) {
str = this.valueOf();
}
let revStr = "";
for (i = str.length - 1; i >= 0; i--) {
revStr += str[i];
}
return revStr;
}
The code we have added to the top of the function body is necessary because, if we call the function on a string variable directly, we will not be passing a string value to it as an argument; it should instead take as its argument the value of the calling string. Now we are ready to add the function as a method to the String prototype:
String.prototype.reverse = reverseString;
We can now call the reverse method directly on a string variable:
let str = "Hello World!";
let strBackwards = str.reverse();
// the value of strBackwards is "!dlroW olleH"
The ability to extend the functionality of native JavaScript objects using their prototype property is frowned upon in some quarters, particularly if the extended object will be used in other scripts further down the line, because it increases the likelihood of inadvertently introducing difficult to trace bugs into the code. We would recommend that you avoid doing so unless the extended object will only ever be used in your own code. And even then, think carefully before doing so.
String concatenation is the process of joining two or more strings together to create a longer string, and it is something you will find yourself doing frequently in your scripts. The string fragments to be joined may be string literals, string variables, or expressions. And, as with many things in JavaScript, there are alternative methods available for concatenating strings.
One of the simplest ways of concatenating strings is a method often used to wrap long passages of text over multiple lines in the code, namely the use of the backslash character at the end of a line of text to indicate that the string continues on the next line. Strictly speaking we should probably not even call this concatenation, since what we are essentially doing is breaking up a large chunk of text into more manageable bites in order to keep our code tidy, but it's a useful technique to know.
The HTML code below creates a web page that displays three buttons, each displaying the title of a different poem. If the user clicks on one of the buttons, all or part of the poem whose title appears on that button will be displayed on the page. Here is the code:
<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>JavaScript Demo 16a</title>
<style>
.center { text-align: center; }
p {
text-align: left;
display: inline-block;
margin: 1em auto;
}
button { min-width: 10em; }
</style>
<script>
let casabianca = "The boy stood on the burning deck<br>\
Whence all but he had fled;<br>\
The flame that lit the battle's wreck<br>\
Shone round him o'er the dead.<br><br>\
Yet beautiful and bright he stood,<br>\
As born to rule the storm;<br>\
A creature of heroic blood,<br>\
A proud, though child-like form.<br><br>\
The flames rolled on – he would not go<br>\
Without his Father's word;<br>\
That father, faint in death below,<br>\
His voice no longer heard.";
let godAndSoldier = "God and the soldier<br>\
All men adore<br>\
In time of trouble,<br>\
And no more;<br>\
For when war is over<br>\
And all things righted,<br>\
God is neglected -<br>\
The old soldier slighted.";
let ifrk = "If you can keep your head \
when all about you<br>\
Are losing theirs and \
blaming it on you;<br>\
If you can trust yourself \
when all men doubt you,<br>\
But make allowance for \
their doubting too:<br>\
If you can wait and not \
be tired by waiting,<br>\
Or, being lied about, \
don't deal in lies,<br>\
Or being hated don't \
give way to hating,<br>\
And yet don't look too good, \
nor talk too wise;<br>\<br>\
If you can dream - and not \
make dreams your master;<br>\
If you can think - and not \
make thoughts your aim,<br>\
If you can meet with \
Triumph and Disaster<br>\
And treat those two impostors \
just the same:.<br>\
If you can bear to hear \
the truth you've spoken<br>\
Twisted by knaves to make \
a trap for fools,<br>\
Or watch the things you gave \
your life to, broken,<br>\
And stoop and build'em up \
with worn-out tools;";
function displayVerses ( title, author, verses ) {
document.getElementById("title").innerHTML = title;
document.getElementById("author").innerHTML = author;
document.getElementById("verses").innerHTML = verses;
}
</script>
</head>
<body>
<div class="center">
<h1>Poetry Page</h1>
<h2>Select a title:</h2>
<button onClick="displayVerses('Casabianca', 'Felicia Dorothea Hemans', casabianca)">Casabianca</button>
<button onClick="displayVerses('God and the Soldier', 'Anonymous', godAndSoldier)">God and the Soldier</button>
<button onClick="displayVerses('If', 'Rudyard Kipling', ifrk)">If</button>
<h3 id="title"></h3>
<h4 id="author"></h4>
<p id="verses"></p>
</div>
</body>
</html>
Copy and paste this code into a new file in your HTML editor, save the file as javascript-demo-16.html, open the file in a web browser, and click on each of the buttons in turn. You should see something like the following:

Clicking on a button displays all or part of a poem
The second method of concatenating strings is to use JavaScript's addition operators (+ and +=). In fact, we can do something very similar to what we did in the previous example using the + operator instead of the backslash. For example, we could do this:
let casabianca = "The boy stood on the burning deck<br>" +
"Whence all but he had fled;<br>" +
"The flame that lit the battle's wreck<br>" +
"Shone round him o'er the dead.<br><br>" +
"Yet beautiful and bright he stood,<br>" +
"As born to rule the storm;<br>" +
"A creature of heroic blood,<br>" +
"A proud, though child-like form.<br><br>" +
"The flames rolled on – he would not go<br>" +
"Without his Father's word;<br>" +
"That father, faint in death below,<br>" +
"His voice no longer heard.";
This code works, and will produce exactly the same result as before. There is an obvious drawback to using the addition operator in this way, however. Instead of enclosing the whole string in one set of quotes, every line must now be enclosed in its own set of quotes. We now have more typing to do without having really gained anything in terms of making our code tidier or more compact. In fact, there is now slightly more code because of all the quotes.
Where the addition operators come into their own is in situations where we need to concatenate a number of string literals and string variables to create new, complex string variables. The HTML code below creates a web page that displays a table representing the final league table for the 2018-2019 season of the English Premier League - the top level of the English football league system.
<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>JavaScript Demo 17</title>
<style>
th, td {
border: 1px solid grey;
padding: 0.25em 0.5em;
text-align: center;
font-size: smaller;
}
table {
margin: auto;
border-collapse: collapse;
}
.center { text-align: center; }
.team { text-align: left; }
</style>
<script>
let teams = ["Manchester City", "Liverpool", "Chelsea", "Tottenham Hotspur", "Arsenal", "Manchester United", "Wolverhampton Wanderers", "Everton", "Leicester City", "West Ham United", "Watford", "Crystal Palace", "Newcastle United", "Bournemouth", "Burnley", "Southampton", "Brighton & Hove Albion", "Cardiff City", "Fulham", "Huddersfield Town"];
let played = [38, 38, 38, 38, 38, 38, 38, 38, 38, 38, 38, 38, 38, 38, 38, 38, 38, 38, 38, 38];
let won = [32, 30, 21, 23, 21, 19, 16, 15, 15, 15, 14, 14, 12, 13, 11, 9, 9, 10, 7, 3];
let drawn = [2, 7, 9, 2, 7, 9, 9, 9, 7, 7, 8, 7, 9, 6, 7, 12, 9, 4, 5, 7];
let lost = [4, 1, 8, 13, 10, 10, 13, 14, 16, 16, 16, 17, 17, 19, 20, 17, 20, 24, 26, 28];
let goalsFor = [95, 89, 63, 67, 73, 65, 47, 54, 51, 52, 52, 51, 42, 56, 45, 45, 35, 34, 34, 22];
let goalsAgainst = [23, 22, 39, 39, 51, 54, 46, 46, 48, 55, 59, 53, 48, 70, 68, 65, 60, 69, 81, 76];
let goalDifference = [72, 67, 24, 28, 22, 11, 1, 8, 3, -3, -7, -2, -6, -14, -23, -20, -25, -35, -47, -54];
let points = [98, 97, 72, 71, 70, 66, 57, 54, 52, 52, 50, 49, 45, 45, 40, 39, 36, 34, 26, 16];
let leagueTable = "";
function displayTable() {
leagueTable += "<table><caption><h2>2018/2019 Season</h2></caption>\
<thead><tr><th>#</th><th>Team</th><th>Pl</th><th>W</th><th>D</th>\
<th>L</th><th>F</th><th>A</th><th>GD</th><th>Pts</th></tr></thead><tbody>";
for (let i = 0; i < teams.length; i++ ) {
leagueTable += "<tr>";
leagueTable += "<td>" + (i + 1) + "</td>";
leagueTable += "<td class='team'>" + teams[i] + "</td>";
leagueTable += "<td>" + played[i] + "</td>";
leagueTable += "<td>" + won[i] + "</td>";
leagueTable += "<td>" + drawn[i] + "</td>";
leagueTable += "<td>" + lost[i] + "</td>";
leagueTable += "<td>" + goalsFor[i] + "</td>";
leagueTable += "<td>" + goalsAgainst[i] + "</td>";
leagueTable += "<td>" + goalDifference[i] + "</td>";
leagueTable += "<td>" + points[i] + "</td>";
leagueTable += "</tr>";
}
leagueTable += "<tfoot><tr><td colspan='10'>\
<strong>Key:</strong><br><br>\
<strong>Pl</strong> = Played\
<strong>W</strong> = Won\
<strong>D</strong> = Drawn\
<strong>L</strong> = Lost<br>\
<strong>F</strong> = For\
<strong>A</strong> = Against\
<strong>GD</strong> = Goal difference\
<strong>Pts</strong> = Points<br><br>\
</td></tr></tfoot></table>";
document.getElementById("leagueTable").innerHTML = leagueTable;
}
</script>
</head>
<body onload="displayTable()">
<div class="center">
<h1>English Premier League</h1>
<div id="leagueTable"></div>
</div>
</body>
</html>
Copy and paste this code into a new file in your HTML editor, save the file as javascript-demo-17.html, and open the file in a web browser. You should see something like the following:
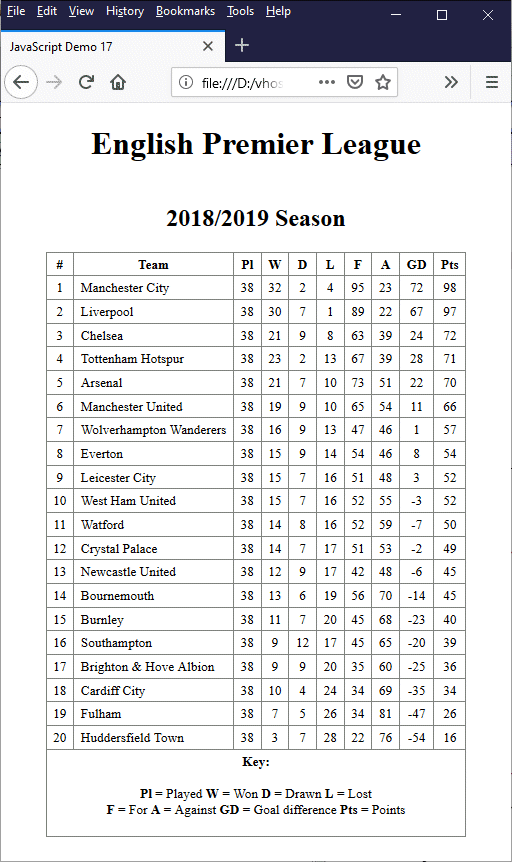
The page displays the Premier League table for 2018/2019
The table data consists of several JavaScript arrays, each holding either text or numerical data. The displayTable() function uses a combination of the backslash character and the two addition operators (+ and +=) to generate the string containing the HTML code for the table, which is made up of both string literals and array elements.
We could of course have created this table without using JavaScript, but the purpose of this exercise was to demonstrate the use of the addition operators to concatenate strings. It also demonstrates the power of JavaScript in terms of being able to manipulate and combine raw data with HTML code to create major elements of a web page.
When we are creating strings that contain both string literals and variables, we can use template literals (we mentioned these earlier). A template consists of string literals and variables between a pair of backticks (as opposed to double or single quotes). We don't need to use the addition operator; we just need to enclose all variable names within a pair of curly braces, prefixed with a dollar sign (${...}).
Using template literals, we could re-write the for statement in our displayTable() function as follows:
for (let i = 0; i < teams.length; i++ ) {
leagueTable += `<tr><td>${i + 1}</td><td class='team'>${teams[i]}</td>
<td>${played[i]}</td><td>${won[i]}</td><td>${drawn[i]}</td>
<td>${lost[i]}</td><td>${goalsFor[i]}</td><td>${goalsAgainst[i]}</td>
<td>${goalDifference[i]}</td><td>${points[i]}</td></tr>`;
}
As you can see, this code is somewhat more compact than the original version, but it does exactly the same thing. One advantage of using template literals is that, because the string is enclosed within backticks, any double or single quotes forming part of the string itself do not need to be escaped (obviously if the string contains backticks, the backticks will need to be escaped).
The only issue you may wish to consider is that, while most modern browsers support template literals, Microsoft's Internet Explorer does not support their use at all, and Microsoft Edge provides only partial support. We tend to take the view that, given the relatively insignificant market share enjoyed by these browsers and the fact that there are numerous freely available alternatives, there is no compelling reason not to use template literals.
The JavaScript String object also has its own concatenation method, concat(). This method concatenates the arguments passed to it, which can be either string literals or string variables, with the calling string. For example, we could rewrite the for statement in our displayTable() function yet again like this:
for (let i = 0; i < teams.length; i++ ) {
leagueTable = leagueTable.concat("<tr><td>", i + 1,
"</td><td class='team'>", teams[i], "</td><td>",
played[i], "</td><td>", won[i], "</td><td>",
drawn[i], "</td><td>", lost[i], "</td><td>",
goalsFor[i], "</td><td>", goalsAgainst[i],
"</td><td>", goalDifference[i], "</td><td>",
points[i], "</td></tr>");
}
This code certainly works, and we can split a long sequence of function arguments over several lines without having to use the backslash character at the end of each line, but we are back to surrounding string literals with double or single quotes. However, the biggest argument against using concat() is that, in performance tests, it has been found to be several times slower than using the addition operator (+) to concatenate strings.
The JavaScript String object provides several methods that allow us to work with substrings in various ways. The method we use in a particular situation will depend on what exactly we are trying to achieve. For example, we might simply wish to find the first occurrence of a word or phrase in a long passage of text, or we might want to replace every occurrence of that word or phrase with a different word or phrase.
Let's start with something simple. We'll assume that all we want to do at the moment is check whether a particular word or phrase occurs within a block of text. To do this, we could use the String object's includes() method. The following code illustrates how this method is used:
let rhyme = "Hickory, dickory, dock. The mouse ran up the clock.";
let bool = rhyme.includes("mouse");
// the value of bool is "true"
The first argument passed to includes() must be a string value. The includes() method also accepts an integer value as its (optional) second argument that specifies the position within the calling string at which the search should commence. If no second argument is supplied, the search starts at the beginning of the string. The includes() method returns true if it finds the specified string value. Otherwise, it returns false.
Obviously, the usefulness of the includes() method, is somewhat limited. it does not, for example, tell us how many times a word or phrase occurs within a given text. Nor does it tell us where within the text the word or phrase can be found. Bear in mind also that this method is case sensitive. If all we want to do is check for the presence or absence of a search term, it will probably suffice. If we want to do something more complicated, we'll need to use more powerful methods.
As we will see, it is often the case that we will need to use two or more of the String object's methods to carry out a particular task. Let's start by thinking about how we might implement a typical "search and replace" script. It just so happens that the String object has both a search() method and a replace() method, so it seems logical to start by looking at how we could use these methods to implement the required functionality.
We'll start by looking at the search() method, which searches the calling string for a substring matching the string or regular expression passed to it as an argument, and returns the starting position of the first match found (or -1 if no match is found). The search() method tells us whether a given search term exists within a string, and if so, the location within the string of the first occurrence of that search term.
The HTML code below creates a web page that displays the text of Abraham Lincoln's famous Gettysburg Address. It includes an input field for a search term, and a "Search" button to enable the user to search for a word or phrase within the text. Here is the code:
<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>JavaScript Demo 18</title>
<style>
p {
margin: 2em auto 1em;
}
.textbox {
text-align: left;
width: 80%;
display: inline-block;
padding: 2em;
border: 1px solid;
}
.center { text-align: center; }
</style>
<script>
function searchText() {
let str = document.getElementById("txt").innerHTML.trim();
let searchTerm = document.getElementById("searchterm").value.trim();
if (searchTerm != "") {
let occursAt = str.search(searchTerm);
if (occursAt == -1) {
alert("The search term was not found.");
}
else {
alert("The search term was found at position " + occursAt + ".");
}
}
else {
alert("Please enter a search term.");
document.getElementById("searchterm").value = "";
}
}
</script>
</head>
<body>
<div class="center">
<h1>The Gettysburg Address</h1>
<h2>Abraham Lincoln</h2>
<p>
<label>Search term: </label><input type="text" id="searchterm">
<button onclick="searchText()">Search</button>
</p>
<p class="textbox" id="txt">
Four score and seven years ago our fathers brought forth on this continent, a new nation, conceived in Liberty, and dedicated to the proposition that all men are created equal.<br><br>Now we are engaged in a great civil war, testing whether that nation, or any nation so conceived and so dedicated, can long endure. We are met on a great battle-field of that war. We have come to dedicate a portion of that field, as a final resting place for those who here gave their lives that that nation might live. It is altogether fitting and proper that we should do this.<br><br>But, in a larger sense, we can not dedicate - we can not consecrate - we can not hallow - this ground. The brave men, living and dead, who struggled here, have consecrated it, far above our poor power to add or detract. The world will little note, nor long remember what we say here, but it can never forget what they did here. It is for us the living, rather, to be dedicated here to the unfinished work which they who fought here have thus far so nobly advanced. It is rather for us to be here dedicated to the great task remaining before us - that from these honored dead we take increased devotion to that cause for which they gave the last full measure of devotion - that we here highly resolve that these dead shall not have died in vain - that this nation, under God, shall have a new birth of freedom - and that government of the people, by the people, for the people, shall not perish from the earth.
</p>
</div>
</body>
</html>
You might have noticed that we call the String object's trim() method on both the text we want to search, and on the text entered by the user in the search box. This method removes leading and trailing whitespace characters from the calling string. The text we want to search might contain superfluous whitespace characters due to the way the HTML code is generated by the HTML editor. In the case of user input (form data, for example), we need to anticipate the possible inclusion of unwanted leading or trailing white space characters.
Copy and paste this code into a new file in your HTML editor, save the file as javascript-demo-18.html, and open the file in a web browser. You should see something like the following:

The page displays some text, and provides a simple search facility
Try typing various words or phrases into the search box and clicking on the "Search" button. The following screenshot is the result of a search for the term "father":
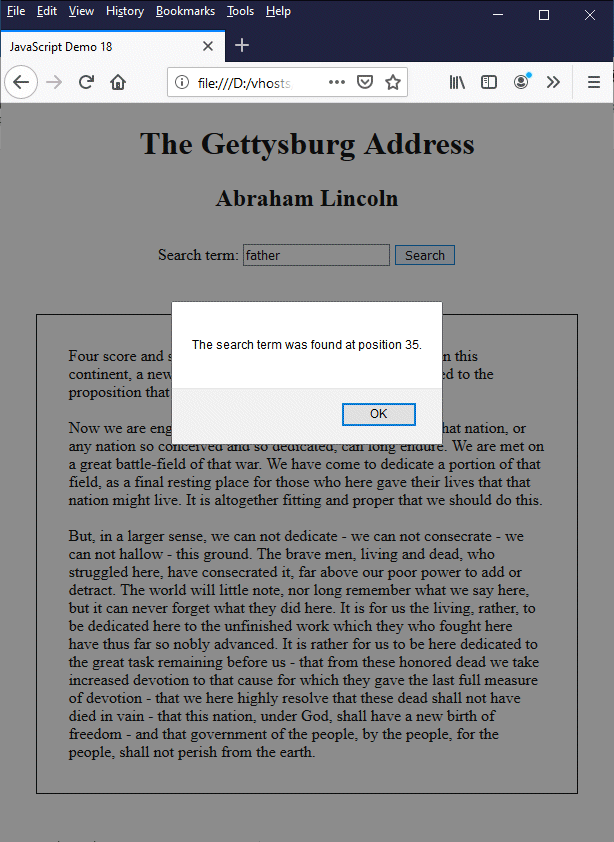
The result of searching for "father"
Obviously, the functionality we have implemented here is fairly limited. Upon clicking on the search button we will see a dialog box, the contents of which will depend on what text is entered in the search box. If we leave the box blank, we are asked to enter a search term. If we enter a search term that does not appear in the text, we are informed that the search term was not found.
If our search term does appear in the text, we are informed of the character position within the text at which the first occurrence starts. How useful is this? On its own, probably not very useful, because in order to visually locate the word or phrase of interest the user is expected to count off character positions from the start of the text. But we have to start somewhere.
Before we move on, there are one or two things to note. First of all, if we are looking for a simple word or phrase, we can achieve exactly the same functionality using the indexOf() method, which is faster than search(). We could replace
let occursAt = str.search(searchTerm);
with
let occursAt = str.indexOf(searchTerm);
The difference between the two functions is that search() takes a regular expression as its argument (if a string value is passed to search() as an argument, it is converted to a regular expression). The first argument passed to indexOf() must be a string value. The indexOf() method also accepts an integer value as its (optional) second argument that specifies the position within the calling string at which the search should commence. If this argument is not supplied, the search starts at the beginning of the string.
Note that the position of the start of the search term reported by both search() and indexOf(), if found, is actually one less than its actual position in the string from the user's point of view, because character positions in strings are indexed from zero. We could make our code a tiny bit more user friendly by adding one to the character position reported by search() or indexOf() before we output the value to the user. So for example, we could replace
alert("The search term was found at position " + occursAt + ".");
with
alert("The search term was found at position " + (occursAt + 1) + ".");
Another thing to note is that both of these methods are case sensitive. A search for "Father", as opposed to "father", would result in the message "The search term was not found.". We could of course do something about that relatively easily by converting both the search string and the text to be searched to lower case when we want to perform a search. For example:
let occursAt = str.toLowerCase().search(searchTerm.toLowerCase());
What we've done here is to call the toLowerCase() method on both the str variable and the searchTerm variable. This method is executed on both variables before the search() method is executed (we'll be looking at the String object's case conversion methods in a little more detail later on).
For the sake of completeness we should mention here that there is a method very similar to indexOf(), called lastIndexOf(), that does exactly the same thing as indexOf() except that it searches (as the name suggests) for the last instance of the search term in the calling string, searching backwards, either from the end of the string or from the position specified by the (optional) second argument.
Given the limited usefulness, from a user's point of view, of knowing the numeric position of a substring in a text, it might be better to enable the user to locate the occurrence of a substring visually. In fact, it is often the case that if a user is searching for a word or phrase in a text, they want to find all occurrences of that word or phrase, not just the first (or last) occurrence.
It would be really nice, for example, if we could get our script to highlight every occurrence of the search term within a text so that the user could visually locate those occurrences, without having to undertake the tedious process of counting characters. In fact, we're going to create a web page that allows the user to type or paste some text into a text field, and then use a search facility similar to the one we saw in the last example to look for all instances of their chosen search term. Here is the HTML code:
<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>JavaScript Demo 19</title>
<style>
#texttosearch {
width: 80%;
margin: 1em auto;
height: 300px;
padding: 1em;
border: solid 1px;
text-align: left;
overflow: auto;
}
button { min-width: 8em; }
.center { text-align: center; }
</style>
<script>
function searchText() {
let textToSearch = document.getElementById("texttosearch").innerHTML.trim();
let searchTerm = document.getElementById("searchterm").value.trim();
if (textToSearch == "") {
alert("You have not entered any text.");
document.getElementById("texttosearch").value = "";
}
else if (searchTerm == "") {
alert("You have not entered a search term.");
document.getElementById("searchterm").value = "";
}
else
{
let includesStr = textToSearch.includes(searchTerm);
if (!includesStr) {
alert("The search term was not found.");
}
else {
clearSearch()
textToSearch = textToSearch.replace(searchTerm, `<mark>${searchTerm}</mark>`);
document.getElementById("texttosearch").innerHTML = textToSearch;
}
}
}
function clearSearch() {
let textToSearch = document.getElementById("texttosearch").innerHTML.trim();
textToSearch = textToSearch.replace("<mark>", "");
textToSearch = textToSearch.replace("</mark>", "");
document.getElementById("texttosearch").innerHTML = textToSearch;
}
function clearText() {
document.getElementById("texttosearch").innerHTML = "";
}
</script>
</head>
<body>
<div class="center">
<h1>Text Search Utility</h1>
<h2>Please enter some text:</h2>
<div id="texttosearch" contenteditable="true"></div>
<p><label>Search: </label><input type="text" id="searchterm"></p>
<p>
<button onclick="searchText()">Search</button>
<button onclick="clearSearch()">Clear search</button>
<button onclick="clearText()">Clear text</button>
</p>
</div>
</body>
</html>
Copy and paste this code into a new file in your HTML editor, save the file as javascript-demo-19.html, open the file in a web browser, and enter or paste in some text (we used an online text generator to generate some random Latin text). Choose a word or phrase from the text you have entered, type it into the search box, and click on the "Search" button. You should see something like the following:
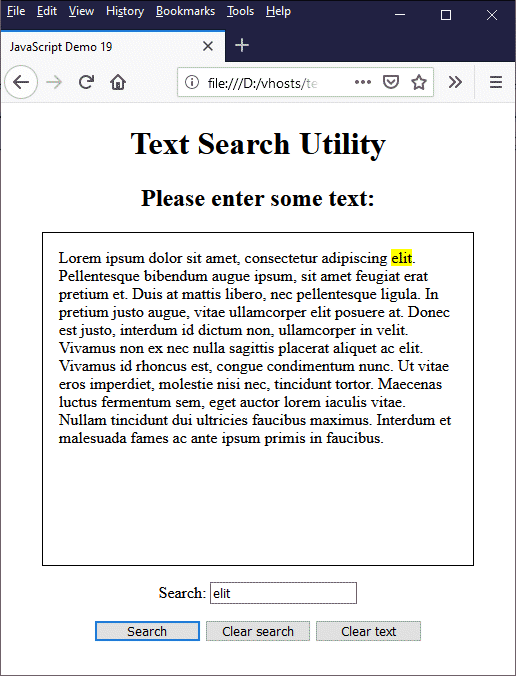
This page allows the user to enter some text and search for a word or phrase
If you experiment for a while, you will find that the script works reasonably well, up to a point. Most of the code should be fairly self-explanatory, but there are a few things to note before we consider how we can improve things. First of all, we have used a <div> element, with its contenteditable attribute set to true, for the main text input area. We use the <div> element in preference to a <textarea> element, because there is no way to highlight text within a <textarea> element programmatically.
The next thing to note is that we have used the simple includes() method to check whether our search term is present within the text:
let includesStr = textToSearch.includes(searchTerm);
if (!includesStr) {
alert("The search term was not found.");
}
This function simply returns true or false, depending on whether or not the search term can be found. If the search term can't be found, the code generates an appropriate message and exits the function. There is, after all, no point in doing any more work than necessary.
If the search term is present in the text, we go to phase two:
clearSearch();
textToSearch = textToSearch.replace(searchTerm, `<mark>${searchTerm}</mark>`);
document.getElementById("texttosearch").innerHTML = textToSearch;
The first line of code calls the clearSearch() function, which removes any highlighting of text resulting from a previous search (this function can also be invoked by the user clicking on the "Clear search" button).
The next line calls the replace() method on the variable textToSearch, which holds the text to be searched. The replace() method creates a new string which also consists of the text to be searched, but now with the first occurrence of the search term enclosed between the opening and closing <mark>...</mark> tags. These are the HTML tags used to mark text, usually by highlighting it. The result is then assigned to textToSearch. The last line of code sets the updated version of the variable textToSearch as the inner HTML of the <div> element that holds the user supplied text, replacing the existing text.
The clearSearch() function uses the replace() method in a similar fashion, this time to remove the highlighting markup, while the clearText() function clears the <div> element that acts as the main text input box by setting its inner HTML to the empty string.
We said that this script works reasonably well, and it does, but there are a few shortcomings. For a start, it would be nice if we could highlight all occurrences of the search term, and not just the first one. You have probably also noticed, if you have played around with the script for a while, that the search is case sensitive. It would be better if we could find all instances of the search term regardless of case.
It should probably be mentioned at this point that the replace() method will work for multiple instances of a search term if we use a suitable regular expression, together with the global flag (g), instead of a string. However, we can't really expect users to enter regular expressions, and converting user input to a regular expression, although possible, would involve some coding techniques that we don't want to get into just now.
In any case, we would still have the problem of searching for occurrences of the search term in a case-insensitive way, replacing them with appropriately marked-up versions of themselves, and at the same time making sure that the case of each character in the search term is preserved as per the original text. We should probably consider a somewhat different approach to the problem.
We're going to build our own search and replace function. We'll start by copying the text to be searched into a new string variable, which we'll call inputString. We'll then search inputString for every instance of the search term using a loop. As we find each occurrence of the search term, we're going to remove the part of inputString immediately before the search term and add it to another string variable, which we'll call outputString. We'll then remove the search term from inputString, add the required markup to it, and add it to outputString.
Each time the loop executes, it starts searching at the beginning of the updated version of inputString. When no more occurrences of the search term can be found, the remaining text in inputString is added to outputString.
The result is that all of the text from inputString will have been moved across to outputString, together with the markup we have added to each occurrence of the search term. The contents of outputString can now be set as the inner HTML of the <div> element containing the text to be searched, replacing the original contents. Here is the revised HTML code:
<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>JavaScript Demo 20</title>
<style>
#texttosearch {
width: 80%;
margin: 1em auto;
height: 300px;
padding: 1em;
border: solid 1px;
text-align: left;
overflow: auto;
}
button { min-width: 8em; }
.center { text-align: center; }
</style>
<script>
function searchReplace() {
clearSearchReplace();
let textToSearch = document.getElementById("texttosearch").innerHTML.trim();
let searchTerm = document.getElementById("searchterm").value.trim();
let termLength = searchTerm.length;
if (textToSearch == "") {
alert("You have not entered any text.");
document.getElementById("texttosearch").value = "";
}
else if (searchTerm == "") {
alert("You have not entered a search term.");
document.getElementById("searchterm").value = "";
}
else
{
let includesStr = textToSearch.toLowerCase().includes(searchTerm.toLowerCase());
if (!includesStr) {
alert("The search term was not found.");
}
else {
let inputString = textToSearch;
let outputString = "";
while (true) {
currentPosition = inputString.toLowerCase().indexOf(searchTerm.toLowerCase());
if (currentPosition == -1) {
outputString += inputString.substring(0);
break;
}
outputString += inputString.substring(0, currentPosition)
outputString += `<mark>${inputString.substring(currentPosition, currentPosition + termLength)}</mark>`;
inputString = inputString.substring(currentPosition + termLength);
}
document.getElementById("texttosearch").innerHTML = outputString;
}
}
}
function clearSearchReplace() {
let textToSearch = document.getElementById("texttosearch").innerHTML.trim();
textToSearch = textToSearch.replace(/<mark>/g, "");
textToSearch = textToSearch.replace(/<\/mark>/g, "");
document.getElementById("texttosearch").innerHTML = textToSearch;
}
function clearText() {
document.getElementById("texttosearch").innerHTML = "";
}
</script>
</head>
<body>
<div class="center">
<h1>Text Search Utility</h1>
<h2>Please enter some text:</h2>
<div id="texttosearch" contenteditable="true"></div>
<p><label>Search: </label><input type="text" id="searchterm"></p>
<p>
<button onclick="searchReplace()">Search</button>
<button onclick="clearSearchReplace()">Clear search</button>
<button onclick="clearText()">Clear text</button>
</p>
</div>
</body>
</html>
Copy and paste this code into a new file in your HTML editor, save the file as javascript-demo-20.html, open the file in a web browser, and enter or paste in some text. As with the previous example, choose a word or phrase from the text you have entered (preferably something that occurs more than once), type it into the search box, and click on the "Search" button. This time, you should see something like this:
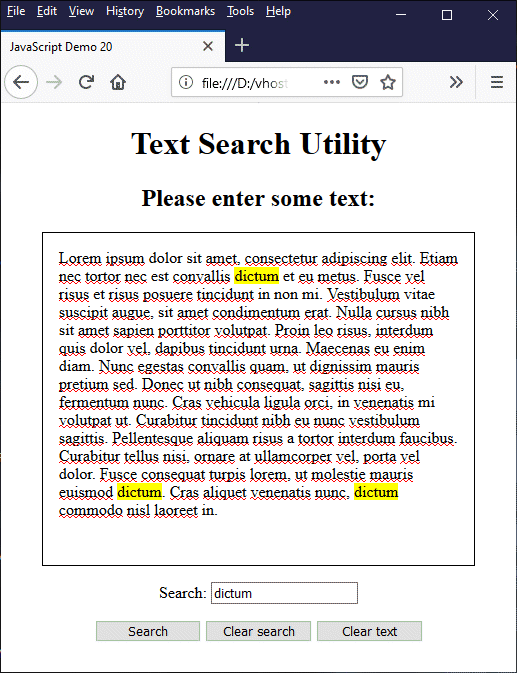
This time, all occurrences of the search term are highlighted
A lot of the code is the same as in the previous example, but there are some important changes. Let's go through these in turn. The first change we've made is to rename the searchText() and clearSearch() functions to searchReplace() and clearSearchReplace() respectively; the new names more accurately reflect what the code is actually doing. We've also moved the call to clearSearchReplace() in the searchReplace() function to the beginning of the searchReplace() fumction's code in case the user initiates a new search without clearing the previous search.
The next change is the addition of the following line to the searchReplace() function:
let termLength = searchTerm.length;
The termLength variable holds the length of the search term, and will be used later when we start extracting occurrences of the search term from the inputString variable.
Next, we replace this line of code:
let includesStr = textToSearch.includes(searchTerm);
with this:
let includesStr = textToSearch.toLowerCase().includes(searchTerm.toLowerCase());
We have used the toLowerCase() method here to change both the text to be searched and the search term text to all lower case characters so that the includes() method will return true if the search term appears in the text to be searched, having been allowed to carry out its search in a non-case-sensitive manner.
We now come to the part of the searchReplace() function in which we have made some fairly radical changes to the original code. Here is the code from our previous example:
textToSearch = textToSearch.replace(searchTerm,`<mark>${searchTerm}</mark>`);
document.getElementById("texttosearch").innerHTML = textToSearch;
and here is the updated version:
let inputString = textToSearch;
let outputString = "";
while (true) {
currentPosition = inputString.toLowerCase().indexOf(searchTerm.toLowerCase());
if (currentPosition == -1) {
outputString += inputString.substring(0);
break;
}
outputString += inputString.substring(0, currentPosition);
outputString += `<mark>${inputString.substring(currentPosition, currentPosition + termLength)}</mark>`;
inputString = inputString.substring(currentPosition + termLength);
}
document.getElementById("texttosearch").innerHTML = outputString;
The first thing we've done here is to create two new string variables. The inputString variable is initially assigned the value of the textToSearch variable, which contains the text to be searched. The outputString variable is an empty string that will eventually hold the marked up version of this text, once the search and replace operation is complete.
The while loop is where the real work gets done. Each time through the loop, we perform a case-insensitive search of inputString using the indexOf() method to find the first occurrence of searchTerm and assign the result to currentPosition. If searchTerm is not found, we extract the section of inputString from currentPosition to the end of the string using the substring() method, add it to outputString, and exit the loop using a break statement.
If searchTerm is found, we extract the section of inputString from the beginning of the string to currentPosition, again using the substring() method, and add it to outputString. Next, we add the opening and closing <mark>...</mark> tags to the occurrence of searchTerm in inputString (the section of inputString from currentPosition to currentPosition + termLength), and add the result to outputString. We use the substring() method one final time to extract the section of inputString between currentPosition + termLength and the end of the string, and assign the result to inputString.
The substring() method takes two arguments. The first argument is an integer value that indicates the position of the first character in the substring. The second argument is optional, and is an integer value indicating the position immediately following the last character in the substring. If the second argument is omitted, substring() returns everything from the position specified by the first argument up to the end of the string.
We could have used substr() instead of substring(). The substr() method takes an optional second argument indicating the length of the substring to be returned. This would have allowed us to pass the termLength variable to substr() as the second argument to extract occurrences of searchTerm from inputString. Unfortunately, substr() is now regarded as a legacy method and may be removed from the language in the future, so we suggest that you avoid using it.
We could also use the slice() method, which is almost identical (see below) to the substring() method, to achieve the same result. For example:
while (true) {
currentPosition = inputString.toLowerCase().indexOf(searchTerm.toLowerCase());
if (currentPosition == -1) {
outputString += inputString.slice(0);
break;
}
outputString += inputString.slice(0, currentPosition);
outputString += `<mark>${inputString.slice(currentPosition, currentPosition + termLength)}</mark>`;
inputString = inputString.slice(currentPosition + termLength);
}
We can briefly summarise the characteristics of the three methods mentioned as follows:
Before we move on to string comparison, there are two more substring-related methods you should know about - startsWith() and endsWith(). These methods are relatively new, and were introduced with EMCAScript 2015.
The startsWith() method returns true or false, depending on whether or not the calling string starts with the substring passed to it as its first argument. The startsWith() method accepts an optional second argument consisting of an integer value that specifies the position within the calling string at which the search should commence (if omitted, this defaults to the beginning of the string).
In similar fashion, the endsWith() method returns true or false, depending on whether or not the calling string ends with the substring passed to it as its first argument. The endsWith() method also accepts an optional second argument, this time consisting of an integer value that specifies the length of the string to be searched (if omitted, this defaults to the length of the calling string).
As with the other substring-related methods we have looked at, both startsWith() and endsWith() are case-sensitive. For either of these methods, in order to perform a search that is not case-sensitive, we must first convert both the calling string and its first argument to all lower case (or all upper case) characters before calling the method.
String comparison in JavaScript is usually achieved using a subset of JavaScript's relational operators. Two strings are compared character by character to determine how they should be ordered alphabetically, or whether they should be considered to be equal. String comparison is typically used when sorting an unordered list of strings into its correct alphabetical order.
Before we look at an example of how this works, we should first look at the mechanism by which JavaScript compares one string with another. As you are probably already aware, JavaScript stores a string as a series of UTF-16 characters. When it compares two strings character by character, it is the first 16-bit UTF code point in each of the two characters that is used as the basis for comparison. The code point with the lowest value is ordered first.
In fact, the algorithm used by JavaScript to compare two strings is relatively simple:
Comparing code points has some side effects that you should be aware of. First of all, upper case characters are sorted before lower case characters. This is because the code points representing the upper case characters A-Z range from 65 to 90, whereas the code points representing the lower case characters a-z range from 97 to 122. This means that the word "Zebra" will be sorted before the word "antelope".
The next point to consider is that, even if the strings we are comparing are restricted to either all upper or all lower case characters, we also often need to consider the special characters used by different languages. To take the German language as an example, the vowels a, o and u are often used with an umlaut (two above the letter, i.e. ä, ö and ü), which changes the sound of the vowel when a word containing them is spoken.
Just to complicate matters even further, both upper case and lower case characters in various languages can have diacritical marks (grave and acute accents, umlauts etc.) above them. Then there are the special characters that appear in many Scandinavian languages. And the unique set of characters in the Greek language (in both its ancient and modern forms). And so on and so forth.
If you are ever required to work with languages other than English, be advised that JavaScript provides the string comparison method localeCompare(), which carries out a comparison based on the language settings in force on the client computer, and on the optional locales and options arguments, if used. For the purposes of this article, we will concentrate on string comparisons using the English language.
One final point we should mention is that some special characters require two UTF-16 code points. If a comparison involving one of these characters is made using a relational operator, only the first code point representing that character will be used as the basis for comparison. It is unlikely, however, that your scripts will require you to carry out such comparisons.
The HTML code below creates a web page that allows the user to enter the name of a town or city into a search box. A "Search" button is provided which, when clicked on by the user, will search for English Premier League (EPL) or English Football League (EFL) teams based in that town or city. If the search is successful, a list containing the name(s) of the team(s) will be displayed below the search box, otherwise an appropriate message will be displayed. Here is the code:
<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>JavaScript Demo 21</title>
<style>
ul {
display: inline-block;
margin: 2em auto;
text-align: left;
}
button { min-width: 8em; }
.center { text-align: center; }
</style>
<script>
let eplEfls = [['Arsenal', 'EPL', 'London'], ['Aston Villa', 'EPL', 'Birmingham'], ['Bournemouth', 'EPL', 'Bournemouth'], ['Brighton & Hove Albion', 'EPL', 'Brighton'], ['Burnley', 'EPL', 'Burnley'], ['Chelsea', 'EPL', 'London'], ['Crystal Palace', 'EPL', 'London'], ['Everton', 'EPL', 'Liverpool'], ['Leicester City', 'EPL', 'Leicester'], ['Liverpool', 'EPL', 'Liverpool'], ['Manchester City', 'EPL', 'Manchester'], ['Manchester United', 'EPL', 'Manchester'], ['Newcastle United', 'EPL', 'Newcastle upon Tyne'], ['Norwich City', 'EPL', 'Norwich'], ['Sheffield United', 'EPL', 'Sheffield'], ['Southampton', 'EPL', 'Southampton'], ['Tottenham Hotspur', 'EPL', 'London'], ['Watford', 'EPL', 'Watford'], ['West Ham United', 'EPL', 'London'], ['Wolverhampton Wanderers', 'EPL', 'Wolverhampton'], ['Barnsley', 'Championship', 'Barnsley'], ['Birmingham City', 'Championship', 'Birmingham'], ['Brentford', 'Championship', 'Brentford'], ['Bristol City', 'Championship', 'Bristol'], ['Blackburn Rovers', 'Championship', 'Blackburn'], ['Cardiff City', 'Championship', 'Cardiff'], ['Charlton Athletic', 'Championship', 'London'], ['Derby County', 'Championship', 'Derby'], ['Fulham', 'Championship', 'London'], ['Huddersfield Town', 'Championship', 'Huddersfield'], ['Hull City', 'Championship', 'Hull'], ['Leeds United', 'Championship', 'Leeds'], ['Luton Town', 'Championship', 'Luton'], ['Middlesbrough', 'Championship', 'Middlesbrough'], ['Millwall', 'Championship', 'London'], ['Nottingham Forest', 'Championship', 'Nottingham'], ['Preston North End', 'Championship', 'Preston'], ['Queens Park Rangers', 'Championship', 'London'], ['Reading', 'Championship', 'Reading'], ['Sheffield Wednesday', 'Championship', 'Sheffield'], ['Stoke City', 'Championship', 'Stoke-on-Trent'], ['Swansea City', 'Championship', 'Swansea'], ['West Bromwich Albion', 'Championship', 'West Bromwich'], ['Wigan Athletic', 'Championship', 'Wigan'], ['Accrington Stanley', 'League One', 'Accrington'], ['AFC Wimbledon', 'League One', 'London'], ['Blackpool', 'League One', 'Blackpool'], ['Bolton Wanderers', 'League One', 'Bolton'], ['Bristol Rovers', 'League One', 'Bristol'], ['Burton Albion', 'League One', 'Burton-upon-Trent'], ['Coventry City', 'League One', 'Coventry'], ['Doncaster Rovers', 'League One', 'Doncaster'], ['Fleetwood Town', 'League One', 'Fleetwood'], ['Gillingham', 'League One', 'Gillingham'], ['Ipswich Town', 'League One', 'Ipswich'], ['Lincoln City', 'League One', 'Lincoln'], ['Milton Keynes Dons', 'League One', 'Milton Keynes'], ['Oxford United', 'League One', 'Oxford'], ['Peterborough United', 'League One', 'Peterborough'], ['Portsmouth', 'League One', 'Portsmouth'], ['Rochdale', 'League One', 'Rochdale'], ['Rotherham United', 'League One', 'Rotherham'], ['Shrewsbury Town', 'League One', 'Shrewsbury'], ['Southend United', 'League One', 'Southend-on-Sea'], ['Sunderland', 'League One', 'Sunderland'], ['Tranmere Rovers', 'League One', 'Birkenhead'], ['Wycombe Wanderers', 'League One', 'High Wycombe'], ['Bradford City', 'League Two', 'Bradford'], ['Cambridge United', 'League Two', 'Cambridge'], ['Carlisle United', 'League Two', 'Carlisle'], ['Cheltenham Town', 'League Two', 'Cheltenham'], ['Colchester United', 'League Two', 'Colchester'], ['Crawley Town', 'League Two', 'Crawley'], ['Crewe Alexandra', 'League Two', 'Crewe'], ['Exeter City', 'League Two', 'Exeter'], ['Forest Green Rovers', 'League Two', 'Nailsworth'], ['Grimsby Town', 'League Two', 'Cleethorpes'], ['Leyton Orient', 'League Two', 'London'], ['Macclesfield Town', 'League Two', 'Macclesfield'], ['Mansfield Town', 'League Two', 'Mansfield'], ['Morecambe', 'League Two', 'Morecambe'], ['Newport County', 'League Two', 'Newport'], ['Northampton Town', 'League Two', 'Northampton'], ['Oldham Athletic', 'League Two', 'Oldham'], ['Port Vale', 'League Two', 'Stoke-on-Trent'], ['Plymouth Argyle', 'League Two', 'Plymouth'], ['Salford City', 'League Two', 'Salford'], ['Scunthorpe United', 'League Two', 'Scunthorpe'], ['Stevenage', 'League Two', 'Stevenage'], ['Swindon Town', 'League Two', 'Swindon'], ['Walsall', 'League Two', 'Walsall']];
function searchForTeams() {
document.getElementById("teamList").innerHTML = "";
let town = document.getElementById("town").value.trim();
let count = 0;
let townLength = town.length;
if (town === "") {
alert("You have not entered a town or city.");
document.getElementById("town").value = "";
}
else if (townLength < 4) {
alert("You must enter at least four characters.");
document.getElementById("town").value = "";
}
else
{
let teamList = "<ul>"
let townLongVersion = "";
for (let i = 0; i < eplEfls.length; i++ ) {
if (eplEfls[i][2].substring(0, townLength).toLowerCase() === town.toLowerCase()) {
if (townLongVersion === "") {
townLongVersion = eplEfls[i][2];
}
else if (townLongVersion !== eplEfls[i][2]) {
break;
}
teamList += "<li>" + eplEfls[i][0] + " (" + eplEfls[i][1] + ")</li>";
count++;
}
}
if (count === 0) {
alert("We did not find any EPL or EFL teams.");
teamList = "";
}
else {
teamList += "</ul>";
let outputString = "<p>We found the following EPL/EFL team(s) in " + townLongVersion + ":</p>";
outputString += teamList;
document.getElementById("teamList").innerHTML = outputString;
}
}
}
function clearSearch() {
document.getElementById("teamList").innerHTML = "";
document.getElementById("town").value = "";
}
</script>
</head>
<body>
<div class="center">
<h1>EPL and EFL (2019/2020)</h1>
<h2>Team Search</h2>
<h3>Please enter a town or city:</h3>
<p><label>Town/city: </label><input type="text" id="town"></p>
<p>
<button onclick=" searchForTeams()">Search</button>
<button onclick="clearSearch()">Clear search</button>
</p>
<div id="teamList" contenteditable="true"></div>
</div>
</body>
</html>
Copy and paste this code into a new file in your HTML editor, save the file as javascript-demo-21.html, open the file in a web browser, enter the name of a town or city in the search box, and click on the "Search" button. Depending on which town or city you have entered, you should see something like this:

The search algorithm finds all matches for the town or city entered
The biggest chunk of code in this case is a rather large array that holds the names of the football clubs, the towns or cities they are based in, and the league to which they currently belong. In fact, it's actually an array of arrays, since JavaScript does not actually have multi-dimensional arrays as such. Each element of the outer array is an array in its own right, and holds the information for a single football club.
You should find most of the code fairly self-explanatory, although there are a few subtleties that probably require some explanation. We'll briefly run through the overall operation of the script first. The user is asked to enter the name of a town or city in the search box after which they are expected to click on the search button to initiate a search (this action calls the searchForTeams() function, which does most of the work).
If the name of a town or city has not been entered by the user, or they have entered fewer than four characters in total, an appropriate message is displayed and the search box is cleared. Otherwise, the code adds the opening <ul> tag to the teamList string variable that will hold the HTML code for our list of teams. A for loop is then used to iterate through the outer array and compare the string entered by the user with the last element of each inner array (i.e. the element that holds the name of a town or city).
Each time a match is found, the code generates an HTML list item containing the name of the corresponding football club and the league in which it currently competes, and adds it to teamList. At the same time, the counter variable count is updated so that we know how many matches have been found. On completion of the loop, if the value of count is zero (because no matches have been found), an appropriate message is displayed and the string variable teamList is set to the empty string.
If at least one match has been found, the closing </ul> tag is added to the end of the teamList string variable. The string variable outputString is then created, which will hold the contents of the information to be displayed. This includes a paragraph containing a brief text message informing the user of the success of their search, and the teamList string that holds the list of teams.
The core of the searchForTeams() function is this block of code:
let townLongVersion = "";
for (let i = 0; i < eplEfls.length; i++ ) {
if (eplEfls[i][2].substring(0, townLength).toLowerCase() === town.toLowerCase()) {
if (townLongVersion === "") {
townLongVersion = eplEfls[i][2];
}
else if (townLongVersion != eplEfls[i][2]) {
break;
}
teamList += "<li>" + eplEfls[i][0] + " (" + eplEfls[i][1] + ")</li>";
count++;
}
}
The string comparison itself occurs in the first if statement within the body of the for loop:
if (eplEfls[i][2].substring(0, townLength).toLowerCase() === town.toLowerCase())
Both the search term (town) and the name of the current town or city (eplEfls[i][2]) are converted to lower case before the comparison is made using the toLowerCase() method. The substring() method is called on eplEfls[i][2], also before the comparison is made, and using townLength as its second argument, to ensure that the strings being compared are the same length.
The townLongVersion variable, which is initially set to the empty string, will hold the full name of the town or city as it appears in the eplEfls array. If, for example, the user enters the search term "Stoke", townLongVersion will be assigned the value "Stoke-on-Trent" on the first iteration of the for loop by the following code:
if (townLongVersion === "") {
townLongVersion = eplEfls[i][2];
}
The next piece of code deals a situation that can arise if the user inputs a search term that matches two different towns or cities. This can happen, despite the fact that the user is required to input at least four characters before a comparison is attempted. For example, if the user inputs the search term "Black", do they mean "Blackburn" or "Blackpool"? The ambiguity is solved by accepting the town or city that is matched first, and ignoring any additional matches. Here is the code that makes this happen:
else if (townLongVersion != eplEfls[i][2]) {
break;
}
Note that we have used the strict equality operator (===) in preference to the standard equality operator (==), although in this particular example, both operators will work. A comparison using the strict equality operator only returns true if both operands match and both operands have the same type. A comparison using the standard equality operator, when used with operands of different types, will attempt to convert the operands to the same type before making the comparison.
We have already seen an example of the JavaScript localeCompare() method in the article "JavaScript Control Structures". In that article, we saw it used as part of the following code, which implements a simple bubble sort function:
function bubbleSort(list){
let sorted, temp;
let n = list.length-1;
let newList = Array.from(list);
do{
sorted = false;
for(let i = 0; i < n; i++) {
if (newList[i+1].localeCompare(newList[i]) === -1) {
temp = newList[i+1];
newList[i+1] = newList[i];
newList[i] = temp;
sorted = true;
}
}
}
while(sorted);
return newList;
}
We could also use the localeCompare() method to implement our searchForTeams() function. We could, for example, replace this code:
for (let i = 0; i < eplEfls.length; i++ ) {
if (eplEfls[i][2].substring(0, townLength).toLowerCase() === town.toLowerCase()) {
if (townLongVersion === "") {
townLongVersion = eplEfls[i][2];
}
else if (townLongVersion !== eplEfls[i][2]) {
break;
}
teamList += "<li>" + eplEfls[i][0] + " (" + eplEfls[i][1] + ")</li>";
count++;
}
}
with this:
for (let i = 0; i < eplEfls.length; i++ ) {
if (eplEfls[i][2].substring(0, townLength).toLowerCase().localeCompare(town.toLowerCase()) === 0) {
if (townLongVersion.localeCompare("") === 0) {
townLongVersion = eplEfls[i][2];
}
else if (townLongVersion.localeCompare(eplEfls[i][2]) !== 0) {
break;
}
teamList += "<li>" + eplEfls[i][0] + " (" + eplEfls[i][1] + ")</li>";
count++;
}
}
The localeCompare() method compares the string passed to it as an argument with the calling string. Here is the syntax:
referenceStr.localeCompare(compareString[, locales[, options]])
A discussion of how the optional arguments are used is somewhat beyond the scope of this page (see the note concerning these arguments in the "String method reference" section at the bottom of this page). The method returns a negative number if referenceStr is ordered before compareString, a positive number if referenceStr is ordered after compareString, and zero if the two strings are the same.
If we are interested in the ordering of two strings (as opposed to simply whether or not they are equal) we can use the return value of the localCompare() method to determine the order. We can also use the relational greater than and less than operators (< and >) for comparing strings. We could, for example, rewrite our bubble sort function like this:
function bubbleSort(list){
let sorted, temp;
let n = list.length-1;
let newList = Array.from(list);
do{
sorted = false;
for(let i = 0; i < n; i++) {
if (newList[i+1] < newList[i]) {
temp = newList[i+1];
newList[i+1] = newList[i];
newList[i] = temp;
sorted = true;
}
}
}
while(sorted);
return newList;
}
A JavaScript string is made up of zero or more UTF-16 characters. It can be considered to be an array of characters, although a string in JavaScript is not an array as such, and prior to the publication of the 5th edition of the ECMAScript standard in 2009, individual characters in a string could not be accessed using standard array notation. This is now possible, although it doesn't work on some older browsers (notably, Internet Explorer version 7 or earlier).
Another thing to be aware of is that, unlike some other programming languages, JavaScript does not have a character data type. Consider the following code fragment:
let str = "Hello World!";
let char = str[6]; // the value of char is "W"
let charType = typeof char; // the value of charType is "string"
A single character within a primitive JavaScript string can be considered to be a substring of that string. We could, for example, use the following code to create the char variable, with exactly the same outcome:
let str = "Hello World!";
let char = str.substring(6, 7); // the value of char is "W"
let charType = typeof char; // the value of charType is "string"
The easiest way to retrieve a single character from a string and maintain compatibility with older browsers is to use the charAt() method, which has been a part of the ECMAScript standard since the beginning. Using this method to create the char variable, our code will look like this:
let str = "Hello World!";
let char = str.charAt(6); // the value of char is "W"
let charType = typeof char; // the value of charType is "string"
The main difference between using the array index notation ([]) and the charAt() method is that, if the index used is less than zero or greater than the length of the string minus one, charAt() will return the empty string, whereas array index notation will return a value of undefined. Note also that you cannot use any of the methods described to change individual characters within a string variable. For example:
let str = "Hello World!";
str[11] = "?"; // this will be ignored
str.charAt(11) = "?"; // generates an error
Primitive JavaScript strings are immutable; to change an individual character in a string, you need to deal with it in exactly the same way you would any other substring, because essentially, that's what it is - a single-character substring. To change the last character of the phrase "Hello World!" from an exclamation mark (!) to a question mark (?), for example, we could do something like this:
let str = "Hello World!";
str = str.substring(0, 11) + "?";
// the value of str is "Hello World?"
Note that, like array elements, individual characters in a string are indexed from zero; the index of the last character in a string is thus the length of the string minus one. Remember however that a string is not an array, and cannot be manipulated in the same way that we can manipulate an array. In order to work with a string in this way, you need to convert it to an array (we'll be looking at how we can do that later in this article).
As we have seen, the UTF-16 characters in a JavaScript string are represented by 16-bit UTF code points. In the vast majority of cases, the characters that make up the strings we work with in our scripts will be represented by a single UTF code point. We should however be aware of, and be able to deal with, instances of characters that consist of two UTF code points. Such characters exist because a single UTF code point consists of an integer in the range 0 to 65535, and can thus represent a maximum of 65536 different characters.
We'll come back to these two-code-point characters shortly. First, we want to look at two string methods that have been part of the ECMAScript standard from the beginning, and that deal specifically with UTF-16 code points - charCodeAt() and fromCharCode().
The charCodeAt() method works in a similar way to the charAt() function we saw earlier, except that instead of returning the character at a given position within the calling string, it returns the 16-bit UTF code point that represents that character (or, if the character is represented by a pair of UTF code points, by the first code point in that pairing). For example:
let str = "The cat sat on the mat.";
let charCode = str.charCodeAt(10);
// the value of charCode is 116
In this example, the character at the tenth position in str is the lower case letter "t", but the value returned by charCodeAt(10) is 116, which is the value of the UTF code point that represents that character.
The fromCharCode() method generates a string from one or more integer values, representing UTF code points, that are passed to it as arguments. For example:
let str = String.fromCharCode(72, 101, 108, 108, 111, 33);
// the value of str is "Hello!"
As we have already said, the charCodeAt() and fromCharCode() methods have been a part of the ECMAScript standard from the beginning, when it was assumed that 65,536 characters, each of which could be represented by a four-digit hexadecimal value, would be sufficient to cover all future needs. Unfortunately, this is no longer the case. The latest version of Unicode as of May 2019 is version 12.1, which contains a total of 137,994 characters (137,766 graphic characters, 163 format characters and 65 control characters). We can expect the number to rise as well, since Unicode has a total of 1,114,112 code points!
This leads us to the question of what happens when we try to use the charCodeAt() and fromCharCode() methods with characters that are not part of the Basic Multilingual Plane (BMP), which is the block of characters that can be represented using a single 16-bit UTF code point. The short answer is that they don't work. Consider the following code snippet:
let str1 = "Have a nice day! 🙂";
let charCode = str1.charCodeAt(str1.length -1);
// the value of charCode is 56898
let str2 = String.fromCharCode(charCode);
// the value of str2 is "�"
Something is obviously not working as we might have expected here. The value returned for our charCode variable is not the correct UTF code for the emoji (in this instance, a smiley face) which we put at the end of our text. In fact, it doesn't appear to be the UTF code for anything meaningful. Indeed, when we pass the value to the fromCharCode() method, it returns a symbol we don't recognise rather than the emoji we started out with.
The reason for this apparent breakdown in communication is that the emoji in question is actually represented by two UTF code points rather than just one. Such an arrangement is known as a surrogate pair. How does this work? It takes a bit of explaining, but bear with us if you can.
First of all, you need to be aware that the Unicode code space is divided into a total of seventeen blocks, each of which contains 65,535 code points, giving 1,114,112 code points in total. The first of these blocks is the Basic Multilingual Plane which we mentioned above, and which contains most, if not all, of the characters we will use with any regularity. The remaining sixteen blocks are called supplementary planes.
The planes in use at the time of writing include the Basic Multilingual Plane (plane 0) the Supplementary Multilingual Plane (plane 1), the Supplementary Ideographic Plane (plane 2), the Supplementary Special-purpose Plane (plane 14), the Supplementary Private Use Area A plane (plane 15) and the Supplementary Private Use Area B plane (plane 16). No characters have so far been assigned to planes 3 through 13.
Each character in the Basic Multilingual Plane (plane 0) is represented by a 4-digit hexadecimal number in the range 0x0000 to 0xFFFF, giving a total of 65,536 code points. The characters in the remaining sixteen planes are represented by a 6-digit hexadecimal number in the range 0x010000 to 0x10FFFF - a total of 1,048,576 code points, taking the overall number of code points to 1,114,112.
In order to represent a character from one of the supplementary planes, UTF-16 must use two 16-bit code points. A direct representation of the first 6-digit hexadecimal number in the range 0x010000 to 0x10FFFF would thus consist of the UTF code units 0x0001 and 0x0000 (a decimal value of 1, followed by a decimal value of 0). Software - including the JavaScript interpreter - would read these values as two separate 16-bit code units because it has no way of knowing that they should be read as a pair of code units. Which is where surrogate pairs come in.
Instead of using a direct representation of the hexadecimal values 0x010000 to 0x10FFFF, UTF-16 uses two surrogate 16-bit hexadecimal values taken from the range 0xD800 to 0xDFFF to represent each of these values. For each character representation, the first surrogate value (known as the high surrogate) is taken from the range 0xD800 to 0xDBFF, and the second (the low surrogate) is taken from the range 0xDC00 to 0xDFFF. Both of these byte ranges can represent a total of 1,024 different code units, so the total number of characters that can be represented is 1,024 × 1,024 (1,048,576).
Because the byte range 0xD800 to 0xDFFF is reserved by UTF-16 solely for the purpose of representing surrogate pairs, software that understands the UTF-16 encoding scheme will know that if it encounters a high surrogate value in a string, it is dealing with a character represented by a surrogate pair, and will subsequently read the low surrogate pair in order to determine which character is being represented.
The surrogate pair representation of a character taken from one of the sixteen supplementary planes is determined as follows:
The concept of surrogate pairs did not exist when the first version of the ECMAScript standard was being formulated. As a consequence, the charCodeAt() method doesn't know how to handle them. If it encounters a supplementary character (i.e. a character whose code point is represented by a surrogate pair) it will return just the first part of the surrogate pair. But there's more. Because a supplementary character is represented by two UTF-16 code points, each supplementary character added to a string increases the length of the string by one, because the string's length property is based on the number of code units.
So let's look at our sample code again and analyse why it didn't do what we expected it to do. Here is the code once more:
let str1 = "Have a nice day! 🙂";
let charCode = str1.charCodeAt(str1.length -1);
// the value of charCode is 56898
let str2 = String.fromCharCode(charCode);
// the value of str2 is "�"
The only supplementary character in the string str1 is the smiley face at the end of the string. The second line of code tries to get the character code for this character by passing an argument of str1.length - 1 to the charCodeAt() method, but since the supplementary character is composed of two UTF-16 code units, the length of the string is one more than the number of characters. As a result, what we are actually retrieving is the second part of a surrogate pair.
As it happens, the fromCharCode() method will produce the correct output if we pass it both parts of a surrogate pair. We could therefore re-write our code to retrieve both parts of the surrogate pair representing our smiley face, and pass these code units to the fromCharCode() method. Here is the revised code:
let str1 = "Have a nice day! 🙂";
let charCode1 = str1.charCodeAt(str1.length -2);
// the value of charCode1 is 55357
let charCode2 = str1.charCodeAt(str1.length -1);
// the value of charCode2 is 56898
let str2 = String.fromCharCode(charCode1, charCode2);
// the value of str2 is "🙂"
This works, but we are not always going to know where the supplementary characters are in a string, or even how many supplementary characters there are. We can't rely on the length property for strings that include supplementary characters, and the charCodeAt() method only returns the first code point in a surrogate pair. It would be far better if we had methods that could retrieve and correctly interpret Unicode code points for the characters in a string without having to concern ourselves with whether or not they were supplementary characters.
Fortunately, the ECMAScript 2015 introduced two new string methods that help us to deal with supplementary characters. The first of these is the codePointAt() method, which returns the actual Unicode code point for a character at a given position in a string (as opposed to part of a surrogate pair).Of course, there is still no guarantee that we will know the starting position of a supplementary character in a string in advance.
What we can do with this method is to loop through the characters in a string using a for...of loop to iterate over the characters in a string and retrieve the code point for each character (remember that a string is an iterable by definition). This will work regardless of whether or not the string contains supplementary characters. For example:
let str = "Have a nice day! 🙂";
let charArray = [];
for (let codePoint of str) {
charArray.push(codePoint.codePointAt(0).toString(16));
}
// the value of charArray is [48,65,6c,6c,6f,21,20,1f642]
We have converted the code points to their hexadecimal format to highlight the fact that the last code unit in charArray is a five-digit hexadecimal number, and must therefore represent a supplementary character. This code unit has a value of 1f642, and represents the Unicode "slightly smiling face" emoticon.
The codePointAt() method essentially does the same thing that the charCodeAt() method does, except that it returns a complete Unicode code point rather than one part of a surrogate pair when it encounters a supplementary character. There is a similar counterpart for the fromCharCode() method which, as you might expect, is called fromCodePoint().
The fromCodePoint() method accepts a sequence of zero or more Unicode code points as its argument, and returns a string containing the characters they represent. For example:
str = String.fromCodePoint(72,101,108,108,111,33,32,128578);
// the value of str is "Hello! 🙂"
The "slightly smiling face" emoticon is one of the graphic characters in the Unicode "Emoticons" block of the Supplementary Multilingual Plane. This block consists of eighty emoticons (or emoji, as they are sometimes called). These pictographs (pictorial symbols) consist mostly of faces depicting various emotional states, although there are a few that represent other things, like hand gestures or animals. The HTML code below creates a web page that displays all of the emoticons in this block.
<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>JavaScript Demo 22</title>
<style>
.center { text-align: center; }
table { border-collapse: collapse; margin: 1em auto; }
td, th { border: 1px solid; padding: 0.25em; }
</style>
<script>
function createSymTable() {
let baseCode = 128512, leftCol = 0;
let symTable = "<table>";
symTable += "<tr><th></th><th>0</th><th>1</th><th>2</th><th>3</th><th>4</th><th>5</th><th>6</th><th>7</th><th>8</th><th>9</th><th>A</th><th>B</th><th>C</th><th>D</th><th>E</th><th>F</th></tr>";
for (let i = 0; i < 5; i++) {
leftCol = baseCode + (i * 16);
symTable += "<tr>";
symTable += "<td>U+" + leftCol.toString(16).toUpperCase().substring(0, 4) + "x</td>";
for (let j = 0; j < 16; j++) {
symTable += "<td>" + String.fromCodePoint(leftCol + j) + "</td>";
}
symTable += "</tr>";
}
document.getElementById("emoticon").innerHTML = symTable;
}
</script>
</head>
<body onload="createSymTable()">
<div class="center">
<h1>Unicode</h1>
<h2>The "Emoticons" Block</h2>
<div id="emoticon"></div>
</div>
</body>
</html>
Copy and paste this code into a new file in your HTML editor, save the file as javascript-demo-22.html, and open the file in a web browser. You should see something like this:
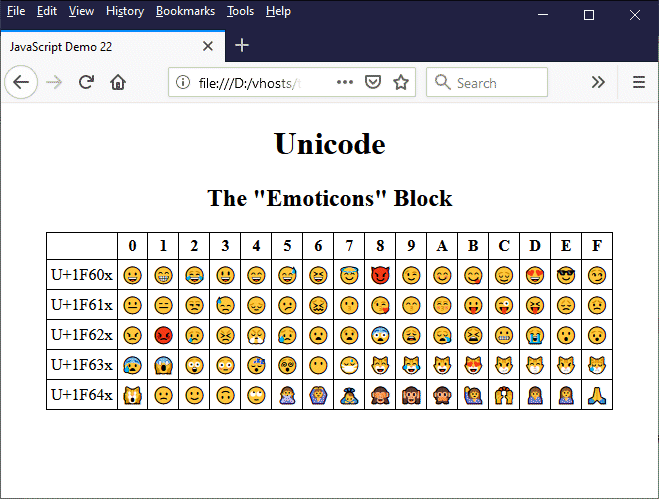
The table displays all of the emoticons in the Unicode "Emoticons" block
Each entry in the left-hand column of the table includes the first four digits of the hexadecimal representation of the code point for a symbol in the corresponding row. The last digit for each symbol is represented by an "x", which should be substituted by the number above the relevant column in order to get the full hexadecimal code unit for a particular symbol. The sole purpose of the characters "U+" in front of the four-digit numbers in the left-hand column is to identify them as Unicode code points.
In virtually all programming, scripting, and markup languages, there are reserved characters that cannot be used directly within the code because they have special meaning within the language concerned. If we need to use one of these reserved characters in our code without invoking its special meaning, we must prefix it with a character called an escape character - usually a backslash ("\").
There are also non-reserved characters that have a special meaning in the language when we "escape" them by prefixing them with the escape character. The combination of the escape character and a reserved (or non-reserved) character is known as an escape sequence. The escape sequences that have special meaning in JavaScript are listed below.
| Sequence | Description |
|---|---|
| \" | Double quote - used to escape double quotes that appear within string literals enclosed within double quotes. |
| \' | Single quote - used to escape single quotes that appear within string literals enclosed within single quotes. |
| \\ | Backslash - used to escape backslash characters that appear within string literals. |
| \b | Backspace - a control character whose purpose is to move the cursor one place to the left on the current line. |
| \f | Form feed - a control character whose purpose is to advance the cursor to the next page. |
| \n | New line - a control character whose purpose is to advance the cursor to the next line. Sometimes used in combination with carriage return to represent a line break. |
| \r | Carriage return - a control character whose purpose is to return the cursor to the beginning of the line. Sometimes used in combination with new line to represent a line break. |
| \t | Horizontal tab - a control character whose purpose is to add a horizontal tab space to a line of text. |
| \v | Vertical tab - a control character whose purpose is to add a vertical tab space to a line of text. |
| \xXX | Unicode character - inserts the character represented by a two-digit hexadecimal code point. Values must be in the range 0x00 to 0xFF. |
| \uXXXX | Unicode character - inserts the character represented by a four-digit hexadecimal code point. Values must be in the range 0x0000 to 0xFFFF. |
| \u{X...XXXXXX} | Unicode character - inserts the character represented by a hexadecimal code point consisting of between one and six hexadecimal digits. Values must be in the range 0x0000 to 0x10FFFF. |
Note that the backspace, form feed, horizontal tab and vertical tab were included in the Unicode specification in order to retain backwards compatibility with legacy systems, but no longer serve any particularly useful purpose. The double and single quote escape sequences, on the other hand, can be very useful if we want to include double and/or single quotes within a string. For example:
str1 = "Suddenly, we heard the cry \"Land ahoy!\"";
// the value of str1 is "Suddenly, we heard the cry "Land ahoy!"";
str2 = '"I don\'t know what\'s gotten into him!", said John.';
// the value of str2 is ""I don't know what's gotten into him!", said John."
Similarly, the escape sequence for the backslash character itself ("\\") is also quite useful because the unescaped backslash character will be interpreted in JavaScript as escaping the character that follows it. If we want to include a backslash character in a string for any reason other than to escape the character that follows it, we must escape it. We might, for example want to output a string that contains a directory path:
str1 = "C:\Users\username\Documents";
// generates a syntax error
str2 = "C:\\Users\\username\\Documents";
// the value of str2 is "C:\Users\username\Documents"
Whether or not we still need to use hexadecimal or decimal numerical escape sequences to represent Unicode characters is questionable, given that virtually all modern browsers can now correctly display the entire range of Unicode code points. On the other hand, because the escape sequences themselves are composed entirely of ASCII characters, their use precludes any problems that might arise due to the encoding used to save or transmit files.
The new line ("\n") and carriage return ("\r") escape sequences are, to all intents and purposes, interchangeable in JavaScript, although we tend to only use "\n". One thing to note here is that, most of the time, the text output created by JavaScript forms part of an HTML document. HTML ignores newline characters in strings, so using the newline in a long text passage to break it down into multiple lines is not going to work unless we format the text to be output using the HTML <pre> element:
str1 = "The boy stood on the burning deck\nWhence all but him had fled;";
\\ the text output appears on a single line
str2 = "<pre>The boy stood on the burning deck\nWhence all but him had fled;</pre>";
\\ the text output has a line break after the word "deck"
Note, however, that by default, the <pre> element formats text by default with a fixed width font. You could of course style the <pre> element to suit your requirements, but it is probably far simpler to just replace the new line escape sequence with an HTML break tag:
str = "The boy stood on the burning deck<br>Whence all but him had fled;";
\\ the text output has a line break after the word "deck"
A diacritical mark is a symbol that appears above, below, or adjacent to an alphanumeric character, usually in order to modify the way in which that character sounds when spoken, but sometimes to modify the meaning of that character. Diacritical marks often appear, for example, in mathematical and scientific notation.
Diacritical marks do not appear in the English language, except for certain non-native words that we have "borrowed" from other languages, like café, déjà vu etc. Most other European languages have many commonly used words that include characters with diacritical marks such as accents and umlauts. Such characters are commonly referred to as composite characters because they are formed from a base character and a diacritical mark. The lower case character "a", for example, is the base character for "à", "á", "â", "ä", "ã", "å", and "ā".
Most of these composite characters are now represented by a single code point in the Universal Coded Character Set (UCCS), but you may occasionally need to add one or more diacritical marks to a base character in order to output a character that is not yet represented in the Unicode character set. UTF-16 allows us to add diacritical marks to base characters by creating our own composite characters.
Despite the fact that most if not all of the composite characters included in a particular language are now represented in the UCCS, we often come across situations in mathematics or science where a particular kind of notation is not represented. In mathematics, for example, a dot over a number is sometimes used to indicate that the number is recurring. For example, instead of writing
1 + 2/3 = 1.666666...
we could simply put a dot over the first digit (6) following the decimal point. There is no specific Unicode representation for a decimal digit with a dot over it, so we have to create our own composite character. We do this by adding the "Combining dot above" (U+0307) diacritical character, as follows:
str = "1 + <sup>2</sup>/<sub>3</sub> = 1.6<sup style='position: relative; left: -4px; font-weight: bold;'>\u0307</sup>";
As you will no doubt have noticed, we have had to use CSS to position the dot correctly above the number because, although this particular diacritical mark will sit nicely above both upper and lower case alphabetical characters, it doesn't play so nicely with numbers.
There are a couple of things you should be aware of when creating your own composite characters, although they relate to situations that will most likely never affect you. First of all, it is perfectly possible to create composite characters that are visually identical to existing Unicode characters. For example, the e-acute character (é) has a direct representation in Unicode, but we could also use the base character "e" and add the Unicode "Combining acute accent" character (U+0301) to create our own e-acute character. For example:
let str1 = "I had coffee at the café.";
let str2 = "I had coffee at the cafe\u0301.";
When these two strings are output to the screen they are indistinguishable from one another. They are not, however the same. Let's add a bit of extra code:
let str1 = "I had coffee at the café.";
let str2 = "I had coffee at the cafe\u0301.";
let strLen1 = str1.length; // the value of strLen1 is 25
let strLen2 = str2.length; // the value of strLen2 is 26
The combining diacritical character has added one to the length of the string. This does not normally create any problems unless you are carrying out a string comparison for some reason, but it's worth noting.
One final thing to note is that there is a normalize() method that rarely gets a mention in popular JavaScript texts (probably because it is unlikely to ever be needed). This essentially works by replacing a composite character made up from two Unicode code points with a single code point that represents the same character. So we could, for example, do this:
let str1 = "I had coffee at the café.";
let str2 = "I had coffee at the cafe\u0301.".normalize();
let strLen1 = str1.length; // the value of strLen1 is 25
let strLen2 = str2.length; // the value of strLen2 is also 25
Our recommendation would be to always check, before you create a composite character, to make sure there is no existing Unicode representation of that character. It certainly seems somewhat pointless to create a composite character that is already represented, especially if you then "normalize" it to avoid potential problems with string comparison routines.
As we stated earlier, JavaScript string variables are declared by putting quotation marks at the beginning and end of the sequence of characters that make up the string. The quotation marks used can be single quotes, double quotes or backticks, and are formally known as bracket delimiters (sometimes called balanced delimiters). There are no definitive guidelines on which kind of bracket delimiter you should use to declare strings, although there are certain things you can do with strings declared with backticks that deserve special mention. For that reason, we'll put the subject of backticks aside for now and return to it later.
Which leaves us with the question: should I use single or double quotes? It's really up to you as a programmer, unless you are working in a development team environment that has guidelines relating to this subject. There is only one rule you must follow, which is that the quotation marks used to declare a string variable must match; you can't, for example, use a double quote at the beginning of the string and a single quote at the end.
let str = "Hello World!' // this causes problems
We would also recommend that you pick a convention and stick to it. Use either single or double quotes to declare strings, but once you decide which you are going to use, do so consistently.
We have already mentioned one of the potential problems with string variables, which is that if the string itself contains a quotation mark that matches the bracket delimiters used, the JavaScript interpreter will interpret it as the end of the string. Don't be tempted, however, to change the type of bracket delimiter you use just to get around a particular instance of this problem. Consider the following string variable declaration:
let str = 'The story isn't over yet.' // this also causes problems
You might well be tempted to change the bracket delimiter used in order to circumvent the problem. For example, you might do this:
let str = "The story isn't over yet." // this is OK
This certainly solves the problem, but you are now using a different bracket delimiter, which means you are sacrificing consistency in favour of a quick fix. It's actually just as easy to use an escape sequence in this instance:
let str = 'The story isn\'t over yet.' // this is OK too
If we had adopted single quotes as our bracket delimiter, this would be our preferred way of dealing with single quotes appearing within a string variable. Similarly, if we had adopted double quotes as our bracket delimiter, we would use the escape character (i.e. a backslash) to escape any double quotes appearing within the string. Note that double quotes appearing inside a string declared with single quotes do not cause a problem, and neither do single quotes appearing inside a string declared with double quotes.
If we had adopted single quotes as our bracket delimiter, this would be our preferred way of dealing with single quotes appearing within a string variable. Similarly, if we had adopted double quotes as our bracket delimiter, we would use the escape character (i.e. a backslash) to escape any double quotes appearing within the string. Note that double quotes appearing inside a string declared with single quotes do not cause a problem, and neither do single quotes appearing inside a string declared with double quotes.
Using escape sequences essentially frees you from having to worry about which type of quotation mark should be used where in a string. Things can potentially get quite complicated - like when you have a string that contains words with apostrophes, and quoted sentences that contains other quoted sentences. For example:
let str = "John turned to Susan and said, "He said something like 'Don't bring any non-essentials.' . . . I think"."; // this creates an error
Obviously, we have a problem here because our bracket delimiter is a double quote, but we have double quotes inside our string. One tactic often used in this situation is to change the bracket delimiter. In this case, for example, we would change the bracket limiter to a single quote, like this:
str = 'John turned to Susan and said, "He said something like 'Don't bring any non-essentials.' . . . I think".'; // this also creates an error
We still have a problem - two problems in fact - because the grammatically correct way to put a quotation inside a quotation in literature is to use single quotation marks inside double quotation marks. We are thus back to square one. And even if we could (gramatically speaking) use double quotation marks inside double quotation marks, there's still the apostrophe, which we can't replace with a double quotation mark in any case. Better to do this:
str = "John turned to Susan and said, \"He said something like 'Don't bring any non-essentials.' . . . I think\"."; // this is OK
We tend to use double quotes to declare string variables in these pages in preference to single quotes, primarily because apostrophes tend to appear in strings more frequently than double quotation marks, but also to ensure future compatibility with JavaScript Object Notation (JSON) - a widely-used text-based data format in which property names and strings are always declared using double quotes.
As we have seen, template literals are strings that are declared in the same way as standard JavaScript strings, except that instead of using double or single quotes as bracket delimiters, we use the backtick character. One immediately obvious advantage of using backticks is that we don't have to worry about double or single quotation marks appearing inside the string variable itself. For example, we could do this:
str = `John turned to Susan and said, "He said something like 'Don't bring any non-essentials.' . . . I think".`; // no escape characters required
Obviously, if a backtick appears inside a string, we need to escape it, although this is something that hardly ever occurs. At this point, you may be asking yourself the question: "If using backticks as bracket delimiters means I don't have to worry about quotation marks inside strings, why can't I create all strings as template literals?". The short answer, of course, is that you can. But should you?
Template literals are a powerful tool because not only do they allow us to do away with (in most cases at least) escape sequences involving quotation marks, they also allow us to embed variables and expressions directly into a string without having to use string concatenation. For example, the variables created by the following variable declarations have exactly the same value:
let str1 = "If the radius of a circle is " + r + " metres, then the circumference of the circle is " + (2 * pi * r).toFixed(2) + " metres.";
let str2 = `If the radius of a circle is ${r} metres, then the circumference of the circle is ${(2 * pi * r).toFixed(2)} metres.`;
let bool = str1 === str2; // the value of bool is true
The variables and/or expressions included in a template literal act as placeholders for the values represented by those variables and expressions (hence the name template literal). Template literals makes life somewhat easier when we need to create complex string variables because, despite the need to enclose variables and expressions between curly braces and prefix them with a dollar sign ("${...}"), we don't have to use concatenation, which in turn means we don't need to add additional quotation marks or worry about forgetting to include the necessary spaces.
Recent benchmark tests also seem to indicate that, in many cases, template literals are processed faster than strings produced using concatenation. Using template literals for all strings may not be such a good idea, even if it means we never have to worry about quotation marks within strings. There is some additional overhead involved in processing template literals that occurs regardless of whether or not they contain variables and expressions, so using them for strings that don't contain variables and expressions can potentially incur a hit in terms of performance.
We can change the case of a string variable (or part thereof) using the String object's toLowerCase() and toUpperCase() methods. We have already seen several examples of using the toLowerCase() method in various string comparison and string search routines, where we converted sting variables to lower case before carrying out the comparison or search in order to do so in a case-insensitive manner.
The toUpperCase() method works in exactly the same way except that, obviously, it converts characters to upper case rather than lower case. The toUpperCase() method could also be used to convert strings to a single case for the purpose of searching for or comparing strings; in most cases, it doesn't really matter which case is used as long as the operands are all of the same case.
Sometimes, all we want to do is to change a word or phrase to either all upper or all lower case characters. In other situations, we might want to do something a little more challenging. We might, for example, want to "normalise" a block of text by changing it to sentence case (where all sentences begin with a capital letter and everything else appears as lower case text), or we might even want to convert a block of text to title case (where every word begins with a capital letter).
This is the kind of thing you will often see in word processing programs like Microsoft word, which allows you to format selected text in various ways, including changing the case of the selected text in the ways we have just described. Working with text selections in HTML and JavaScript is fairly challenging, so we're not going to go quite that far. Instead, we'll create a HTML page that allows the user to enter some text in a text input field and then transform it in various ways. Here is the code:
<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>JavaScript Demo 23</title>
<style>
#sampletext {
width: 80%;
margin: 1em auto;
height: 200px;
padding: 1em;
border: solid 1px;
text-align: left;
overflow: auto;
}
#outputText {
width: 80%;
margin: 1em auto;
height: 200px;
padding: 1em;
border: solid 1px;
text-align: left;
overflow: auto;
background-color: WhiteSmoke;
}
button { min-width: 8em; margin: 0.5em; }
.center { text-align: center; }
</style>
<script>
function toLower() {
toSentence();
let str = document.getElementById("outputText").innerHTML;
str = str.toLowerCase();
document.getElementById("outputText").innerHTML = str;
}
function toUpper() {
toSentence();
let str = document.getElementById("outputText").innerHTML;
str = str.toUpperCase();
document.getElementById("outputText").innerHTML = str;
}
function toSentence() {
let strTemp = document.getElementById("sampletext").value.toLowerCase().trim();
if (strTemp.length == 0) { return; }
str = strTemp[0].toUpperCase();
strTemp = strTemp.substring(1);
let pos = 0;
while (true) {
pos = strTemp.search(/[.?!]/);
if (pos != -1 && pos < strTemp.length - 1) {
str += strTemp.substring(0, pos + 1);
strTemp = strTemp.substring(pos + 1);
while (strTemp.charCodeAt(0) == 10) {
str += "<br>";
strTemp = strTemp.substring(1);
}
while (strTemp[0] == " ") {
str += " ";
strTemp = strTemp.substring(1);
}
if (strTemp.length > 0) {
str += strTemp[0].toUpperCase();
strTemp = strTemp.substring(1);
}
}
else {
str += strTemp;
break;
}
}
document.getElementById("outputText").innerHTML = str;
}
function toTitle() {
toSentence();
let strTemp = document.getElementById("outputText").innerHTML;
if (strTemp.length == 0) {
return;
}
let str = "", pos = 0;
while (true) {
pos = strTemp.search(/\s[a-z]/);
if (pos!= -1) {
str += strTemp.substring(0, pos + 1) + strTemp[pos + 1].toUpperCase();
strTemp = strTemp.substring(pos + 2);
}
else {
str += strTemp;
break;
}
}
document.getElementById("outputText").innerHTML = str;
}
function clearText() {
document.getElementById("sampletext").value = "";
document.getElementById("outputText").innerHTML = "";
}
</script>
</head>
<body>
<div class="center">
<h1>Change Case Utility</h1>
<h2>Please enter some text:</h2>
<textarea id="sampletext"></textarea>
<h2>Output:</h2>
<div id="outputText"></div>
<p>
<button onclick="toLower()">Lower Case</button>
<button onclick="toUpper()">Upper Case</button><br>
<button onclick="toSentence()">Sentence Case</button>
<button onclick="toTitle()">Title Case</button><br>
<button onclick="clearText()">Clear Text</button>
</p>
</div>
</body>
</html>
Copy and paste this code into a new file in your HTML editor, save the file as javascript-demo-23.html, open the file in a web browser, type or copy and paste some text into the text input field, and experiment with the "Lower Case", Upper Case", Sentence Case" and "Title Case" buttons. Depending on the text you enter and which button you click, you should see something like this:

This page allows you to enter some text and change the case.
The script enables the user to switch the case of the text entered between upper and lower case, sentence case, and title case. Obviously, the facility we have provided is an "all or nothing" approach; the user can't select individual words or phrases and format them. This means that (for example) proper nouns like place names that appear in the middle of a sentence will lose their capitalisation when sentence case is selected.
You can no doubt other discover other shortcomings with the script, but at least it gives you an idea of how we can manipulate strings using the toUpperCase() and toLowerCase() methods. We've also used a few other methods to achieve this functionality, so it mght be useful to run through the critical sections of code and explain what's going on. Here is the code for the toLower() function:
function toLower() {
toSentence();
let str = document.getElementById("outputText").innerHTML;
str = str.toLowerCase();
document.getElementById("outputText").innerHTML = str;
}
This function is fairly straightforward, although it does make use of the toSentence() function, which takes care of any line breaks (we'll see why this is necessary in due course). The string value returned by the toSentence() function is set as the inner HTML of the <div> element that displays the output. The next three lines of code retrieve the text from the output <div>, convert it to all lower case characters using toLowerCase(), and then re-assign it to the output <div>.
The toUpper() function works in an identical manner, except that the output of the toSentence() function, once retrieved from the output <div>, is converted to all upper case characters using toUpperCase() before being re-assigned to the output <div>. Which brings us to the code for the toSentence() function. We start by getting the text entered by the user, converting it to lower case, and getting rid of any unwanted whitespace at the beginning and end of the text:
let strTemp = document.getElementById("sampletext").value.toLowerCase().trim();
Just in case the user attempts to invoke this function without having entered any text, we next check to see if there is any text to process, and if not, exit the function:
if (strTemp.length == 0) { return; }
We start the process of formatting the text as sentence case by capitalising the first letter. We're going to working with a temporary string variable called strTemp that initially holds all of the text we want to convert. As we move through this string making changes, we'll remove the parts we've formatted from strTemp and add them to a string variable called str, which will hold the final result at the end of the process. Here's the first step:
str = strTemp[0].toUpperCase();
strTemp = strTemp.substring(1);
let pos = 0;
The variable str now holds the first character of the output string, converted to upper case, and the strTemp variable holds the rest of the string. The variable pos will be used to keep track of our position in the string at any given time. The rest of the string is processed in a while loop that will iterate until we have found the end of the last sentence. Here's code for the entire loop:
while (true) {
pos = strTemp.search(/[.?!]/);
if (pos != -1 && pos < strTemp.length - 1) {
str += strTemp.substring(0, pos + 1);
strTemp = strTemp.substring(pos + 1);
while (strTemp.charCodeAt(0) == 10) {
str += "<br>";
strTemp = strTemp.substring(1);
}
while (strTemp[0] == " ") {
str += " ";
strTemp = strTemp.substring(1);
}
if (strTemp.length > 0) {
str += strTemp[0].toUpperCase();
strTemp = strTemp.substring(1);
}
}
else {
str += strTemp;
break;
}
}
Each time through the loop, we're looking for an end of sentence character. According to the rules of grammar, this must be a period (or full stop), a question mark, or an exclamation mark. We use the search() method together with the regular expression /[.?!]/ to find the first occurrence of one of these characters in strTemp:
pos = strTemp.search(/[.?!]/);
The rest of the code is nested inside an if statement, and will only execute if we find an end-of-sentence character before reaching the end of the string:
if (pos != -1 && pos < strTemp.length - 1) {
...
...
...
}
If we do find an end of sentence character, the code inside the if statement will execute. The first thing that happens is that all of the characters in the strTemp variable up to and including the end of sentence character are removed from strTemp and appended to the str variable:
str += strTemp.substring(0, pos + 1);
strTemp = strTemp.substring(pos + 1);
There are now two possibilities we need to deal with, since we already know that the sentence we have transferred to str was not the last sentence in strTemp. The first possibility is that the sentence was the last in a paragraph, in which case we need to process one or more newline characters. We achieve this using a while loop that will only be executed if there is a newline character at the beginning of our updated strTemp variable:
while (strTemp.charCodeAt(0) == 10) {
str += "<br>";
strTemp = strTemp.substring(1);
}
If we find a newline character at the first position in strTemp, we add a <br> element to str and remove the newline character from strTemp. Why do we not just move the newline character from strTemp to str? Because str is our output string, and will form the inner HTML of a <div> element. HTML treats newline characters as whitespace (or ignores them if they follow other whitespace characters), so we need to replace each newline character we find with a <br> element. The while loop runs until there are no more newline characters at the first position of strTemp.
If the sentence we just transferred to str was not the last sentence in a paragraph (or even if it was), the next sentence might be preceded by one or more space characters. We need to deal with these too. We again use a while loop, this time to remove any leading spaces from strTemp and add them to str:
while (strTemp[0] == " ") {
str += " ";
strTemp = strTemp.substring(1);
}
Obviously, we don't need to substitute the space characters with anything because HTML recognises the space character. If there is a sequence of whitespace characters in the input string, they will be transferred to the output string, but only one will be displayed because HTML will ignore any spaces after the first one (it also ignores whitespace characters that follow a line break). One side effect of this is that any indentation in the original string will not appear in the output. Well, we did say the script had one or two shortcomings!
The next block of code is a nested if statement that executes if we have not yet reached the end of the input string. It converts the first character in strTemp (this will be the first character of the next sentence) to upper case using the toUpperCase() method, then removes it from strTemp, and appends it to str:
if (strTemp.length > 0) {
str += strTemp[0].toUpperCase();
strTemp = strTemp.substring(1);
}
If the outer if statement does not execute (because we have found no further end-of-sentence characters in strTemp), the else clause is executed. This simply takes all of the remaining characters in strTemp and concatenates them with str, completing the output string:
else {
str += strTemp;
break;
}
The only thing we have left to do now is to set the output string as the inner HTML of the <div> element that displays the output text:
document.getElementById("outputText").innerHTML = str;
We're not going to go into a similarly detailed explanation of how the toTitle() function works, since you are probably quite capable by now of working it out for yourself. Suffice to say that it calls on the toSentence() function to do a lot of the heavy lifting, leaving it to concentrate on looking for lower case characters that appear immediately after a whitespace character (signalling the start of a word), which it then converts to upper case characters.
We have already seen how a string can be seen as an array of individual characters, each of which can be accessed in array-like fashion using its position in the string as an array index. We can also view a string as an array of substrings, separated by some delimiter such as a space or a comma. This can be useful, for example, when we need to deal with data in the form of a comma separated list.
One example of data that is stored in the form of comma separated lists is a comma separated values (CSV) file. CSV files are useful because they allow us to store relatively large amounts of tabular data in a compact form. CSV files are plain text files that are often used to store data that can be used with web pages. They can also be used as input to, or output from, a database.
Each line in a CSV file is a record, and each record consists of one or more fields, separated by commas. Each field contains either text data or numerical data stored as text. In a correctly formatted CSV file, each line will contain the same number of fields. The downside of CSV files is that, apart from the fact that each record is on a separate line and values are comma delimited, the data they contain is otherwise unformatted, making them difficult to read.
One of the methods available to the String object that we have not yet looked at is the split() method, which can parse a string variable that contains one or more substring values delimited by a list separator and return an array containing those values. In order to demonstrate how the split() method works, we're going to create an HTML page that allows the user to copy and paste some raw data from a CSV file into an input field. The page will include a "Create Table" button that, when clicked, will display the data in an HTML table. Here is the code:
<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>JavaScript Demo 24</title>
<style>
#fileContent {
width: 80%;
margin: 1em auto;
height: 200px;
padding: 1em;
border: solid 1px;
text-align: left;
overflow: auto;
}
th, td {
border: 1px solid grey;
padding: 0.25em 0.5em;
text-align: left;
font-size: smaller;
}
th { background-color: WhiteSmoke; }
table {
margin: auto;
border-collapse: collapse;
}
caption {
font-size: 1.2em;
font-weight: bold;
padding: 1em;
}
button { min-width: 8em; margin: 0.5em; }
.center { text-align: center; }
ol {
display: inline-block;
margin: 0em auto 1em;
text-align: left;
}
</style>
<script>
function createTable() {
let strInput = document.getElementById("fileContent").value;
if (strInput.length == 0) { return; }
let strOutput = "", strTemp = "";
strOutput += "<table><caption>File Contents</caption>";
if (document.getElementById("headers").checked == true) {
pos = strInput.indexOf("\n");
strTemp = strInput.substring(0, pos);
strInput = strInput.substring(pos + 1);
let headers = strTemp.split(",");
strOutput += "<thead><tr>";
for (let i = 0; i < headers.length; i++) {
strOutput += `<th>${headers[i]}</th>`;
}
strOutput += "</tr></thead><tbody>";
}
while (true) {
pos = strInput.indexOf("\n");
if (pos != -1 && pos < strInput.length) {
strTemp = strInput.substring(0, pos);
strInput = strInput.substring(pos + 1);
let row = strTemp.split(",");
strOutput += "<tr>";
for (let i = 0; i < row.length; i++) {
strOutput += `<td>${row[i]}</td>`;
}
strOutput += "</tr>";
}
else { break; }
}
strOutput += "</tbody></table><br><br>";
document.getElementById("outputBox").innerHTML = strOutput;
}
function clearInput() {
document.getElementById("fileContent").value = "";
document.getElementById("outputBox").innerHTML = "";
}
</script>
</head>
<body>
<div class="center">
<h1>CSV File Content Viewer</h1>
<h2>Instructions:</h2>
<ol>
<li>Copy the contents of a valid CSV file.</li>
<li>Paste the contents into the text box below.</li>
<li>Check/uncheck "Column headers".</li>
<li>Click on the "Create Table" button.</li>
</ol>
<p>
<label><input type="checkbox" id="headers" checked> Column headers</label><br><br>
<button onclick="createTable()">Create Table</button>
<button onclick="clearInput()">Clear Input</button>
</p>
<textarea id="fileContent"></textarea>
<div id="outputBox"></div>
</div>
</body>
</html>
Copy and paste this code into a new file in your HTML editor, save the file as javascript-demo-24.html, open the file in a web browser. You will need to find a valid CSV file to see how the page functions (instructions on how to do this are included on the page). If you don't have access to any suitable CSV files, you can download the file we used for the screenshot below here. Depending on the file data used, you should see something like the following:

This page accepts raw CSV data and converts it into an HTML table.
When you are ready to copy the data from whatever CSV file you have selected, do not open the file with a spreadsheet program like Microsoft's Excel. Use a basic ASCII text editor (Microsoft Notepad, for example). Also, note that we haven't built any error-handling into the script. If you paste any incorrectly formatted data into the input window, you may well get some output, but it probably won't make a whole lot of sense.
The createTable() function does most of the actual work. Let's briefly look at how this works. The first two lines copy the file contents pasted into the input field by the user to the string variable strInput and check to see if there is any content to process. If not, the code simply exits the function:
let strInput = document.getElementById("fileContent").value;
if (strInput.length == 0) { return; }
The next line declares and initialises the strOutput string variable that will hold the code for the HTML table that will display the file data, and the strTemp string variable that will hold the HTML code for each individual table row as we loop through the file records:
let strOutput = "", strTemp = "";
Now we start to create the HTML code for the table:
strOutput += "<table><caption>File Contents</caption>";
The next block of code is an if statement that only executes if the "Column headers" checkbox on our page is checked. The user should leave this checked (which it will be by default) if the CSV file contains column headers in the first line. The first three lines in this block get the position of the first newline character in strInput, copy all of the text in strInput up to (but not including) the newline character into strTemp, and remove the text and the newline character from strInput:
pos = strInput.indexOf("\n");
strTemp = strInput.substring(0, pos);
strInput = strInput.substring(pos + 1);
Now we get to see the split() method in action. The following line splits strTemp into its individual (comma separated) values and assigns them to the array variable headers:
let headers = strTemp.split(",");
We can now start to build the table header, which will contain the column headers:
strOutput += "<thead><tr>";
Each column header will be represented by a table header (<th>) element. We create the table header elements by looping through the headers array and adding the necessary HTML markup to the header text:
for (let i = 0; i < headers.length; i++) {
strOutput += `<th>${headers[i]}</th>`;
}
On each iteration of the for loop, the HTML code generated is added to strOutput. The final line of code in the if statement completes the HTML code for the table header, and adds the opening tag for the main body of the table:
strOutput += "</tr></thead><tbody>";
The remaining data is now dealt with using a while loop that iterates over strInput to extract the individual records and add the required HTML markup to each. We start by finding the position of first newline character in strInput:
pos = strInput.indexOf("\n");
Most of the remaining code inside the while loop consists of a nested if statement that executes only if we have not encountered the last newline character in strInput. Otherwise, it exits the while loop:
if (pos != -1 && pos < strInput.length) {
...
...
...
}
else { break; }
The code inside the if statement creates the table rows that hold the individual records in the CSV file. It works in much the same way as the code we used to create the column headers, so we are not going to provide a detailed explanation here. Once the markup for each table row has been added to strOutput, the remaining code simply adds the markup to complete the table, and assigns strOutput as the inner HTML of the <div> element we're using as an output box.
Before we leave the subject of strings as arrays, there are a couple of points to be aware of with regard to the split() method.
The table below lists some of the methods available to the JavaScript String object, gives a brief description of each, and provides examples of their use. Note that all string methods return a new value - they do not change the value of the original variable.
| Method | Description |
|---|---|
| charAt() |
Syntax: str.charAt(index) Returns the character at the specified index (position) within a string. For example:
let myStr = "Hello World!"; String positions are indexed from zero, so the argument passed to charAt() must be an integer between zero and one less than the length of the string. If the argument is an integer value outside this range, the empty string is returned. If the argument cannot be converted to an integer or is missing altogether, a default value of zero is used, and the first character of the string is returned. |
| charCodeAt() |
Syntax: str.charCodeAt(pos) Returns an integer value between 0 and 65535 representing the UTF-16 code point value for the character at the specified position within a string or (if the character is a supplementary character that cannot be represented by a single code unit) the first of two code units that represent that code point. For example:
let myStr = "Hello World!"; String positions are indexed from zero, so the argument passed to charCodeAt() must be an integer between zero and one less than the length of the string. If the argument is an integer value outside this range, the value NaN (Not a Number) is returned. If the argument cannot be converted to an integer or is missing altogether, a default value of zero is used, and the UTF-16 code unit corresponding to the first character of the string is returned. |
| codePointAt() |
Syntax: str.codePointAt(index) Returns a value between 0 and 1,114,111 representing the Unicode code point for the character at the position specified by index within a string. For example:
let str = "Hi there! 🙂"; String positions are indexed from zero, so the argument passed to codePointAt() must be an integer between zero and one less than the length of the string. If the argument is an integer value outside this range, or if the argument is missing altogether, the value undefined is returned. |
| concat() |
Syntax: str.concat(str2 [, ...strn]) Concatenates (joins together) two or more strings, and returns the result as a new string. For example:
let str1 = "Hello"; Any strings passed to concat() as arguments are concatenated with the calling string. It is recommended that the assignment operators (+ or +=) are used in preference to the concat() method due to performance considerations (in tests, the assignment operators are usually significantly faster). |
| endsWith() |
Syntax: str.endsWith(searchString [, length]) Returns true or false, depending on whether a string ends with the specified character or string. For example:
let myString = "Hello World!"; The endsWith() method can take an optional length argument that specifies how many characters within the calling string should be considered. For example:
let myString = "Hello World!"; |
| fromCharCode() |
Syntax: String.fromCharCode(num1[, ...[, numN]]) Returns a string created from a sequence of one or more UTF-16 code units, each represented by an integer value in the range 0 - 65535. For example:
let myString = String.fromCharCode(72, 105, 33); Note that the value returned is a string primitive and not a String object. |
| fromCodePoint() |
Syntax: String.fromCodePoint(num1[, ...[, numN]]) Returns a string created from a sequence of one or more Unicode code points, each represented by an integer value in the range 0 - 1,114,111. For example:
let str = String.fromCodePoint(72,105,33,32,128578); Note that the value returned is a string primitive and not a String object. |
| includes() |
Syntax: str.includes(searchString[, position]) Returns true or false, depending on whether or not searchString can be found inside str. For example:
let myString = "Hello World!"; The optional position parameter allows you to specify the position within str at which to begin the search (the default position is 0). Note that the includes() method is case sensitive. For example:
let myString = "Hello World!"; |
| indexOf() |
Syntax: str.indexOf(searchValue [, fromIndex]) Returns an integer value representing the position within str at which the first occurrence of searchValue can be found, or -1 if searchValue is not found. For example:
let myString = "Hello World!"; The optional fromIndex parameter allows you to specify the position within str at which to begin the search (the default position is 0). Note that the indexOf() method is case sensitive. For example:
let myString = "Hello World!"; |
| lastIndexOf() |
Syntax: str.lastIndexOf(searchValue [, fromIndex]) Returns an integer value representing the position within str at which the last occurrence of searchValue can be found, or -1 if searchValue is not found. For example:
let myString = "It's a mad, mad world!"; The optional fromIndex parameter allows you to specify the last position within str at which to begin the search. The default position is +Infinity; if fromIndex is greater than or equal to str.length, the whole string is searched. Note that the lastIndexOf() method is case sensitive. For example:
let myString = "It's a mad, mad world!"; |
| localeCompare() |
Syntax: str.localeCompare(compStr[, locales[, options]])) Returns an integer value, depending on whether str is sorted before compStr (returns a negative integer), after compStr (returns a positive integer), or the two strings are equal (returns 0). For example:
let str1 = "abc", str2 = "bcd"; Note that the rules used to determine the ordering of two strings are subject to regional variations, and will depend on the language settings used by the browser. The optional locales and options arguments (see the ECMAScript Internationalization API 1.0 (ECMA-402 documentation for details) are not fully supported by all browsers at the time of writing. |
| match() |
Syntax: str.match(regexp) Searches a string for a match against a regular expression and returns the result as either an Array object, the content of which depends on the presence or absence of the global (g) flag, or null if no matches are found. If the global flag is used, all results matching the complete regular expression will be returned. If the global flag is not used, only the first complete match is returned. For example:
let str = "The cat sat on the mat."; |
| repeat() |
Syntax: str.repeat(count) Returns a new string which contains the number of copies specified by count of the calling string, concatenated together. For example:
let str = "Mayday!"; The count argument must be a non-negative integer that is less than +Infinity and that does not cause the resulting string to exceed the maximum string size. |
| replace() |
Syntax: str.replace(regexp|substr, newSubstr|function) Returns a copy of the original string in which some or all of the substrings within the original string that match a pattern have been replaced with a new substring. For example:
let str = "My favourite Disney character is Mickey!"; The pattern to be matched is the first argument passed to replace(), and can be either a string or a regular expression. The replacement string is the second argument passed to replace(), and can be either a string literal or the output of a function. Note that if the pattern to be matched is a string, only the first matching substring will be replaced. To replace all matching substrings, use a regular expression together with the global flag (g). For example:
let str = "Let's do it! Yes, Yes, Yes!"; |
| search() |
Syntax: str.search(regexp) Searches the calling string for a substring matching the regular expression passed to search() as an argument, and returns the starting position of the first match found (or -1 if no match is found). For example:
let str = "Charles Dickens is a well-known author."; If a string is passed to the search() method instead of a regular expression, it will automatically be converted to a regular expression. For example:
let str = "Charles Dickens is a well-known author."; |
| slice() |
Syntax: str.slice(beginIndex[, endIndex]) Extracts a substring from the calling string and returns it as a new string. The substring to be extracted starts at the position specified by beginIndex and ends at the position immediately before that specified by the optional endIndex argument. For example.
let str = "All the King's horses ...."; If endIndex is omitted, slice() extracts all characters from the start position to the end of the string. For example:
let str = "All the King's horses ...."; If beginIndex is a negative value, it is treated as str.length + beginIndex. For example:
let str = "All the King's horses ...."; Similarly, if endIndex is negative, it is treated as str.length + endIndex. For example:
let str = "All the King's horses ...."; |
| split() |
Syntax: str.split([separator[, limit]]) Returns an array of strings made up of substrings taken from the calling string using the character(s) identified by separator as the string delimiter within that string. For example:
let str = "one two three four five"; The optional limit argument is a non-negative integer value that specifies how many splits should be used to create the array, thus limiting the number of array elements created. Any text beyond the last split is not included in the array. If limit exceeds the number of splits found, the argument has no effect, and if limit is 0, the array returned is empty. Note that separator can contain multiple characters or even be a regular expression, but the whole character sequence or pattern must be found in order for str to be split. If separator is omitted or is not found in str, the array returned contains a single element consisting of str. If separator appears at the beginning of the string, the array begins with an empty string. Similarly, if separator appears at the end of the string, the array ends with an empty string. If separator is the empty string (""), the elements of the returned array consists of the UTF-16 characters in str. For example:
let str = "Hello!"; |
| startsWith() |
Syntax: str.startsWith(searchString[, position]) Returns true or false, depending on whether a string starts with the specified character or string. For example:
let myString = "Hello World!"; The startsWith() method can take an optional position argument that specifies the position within the calling string from which to start the search. If the argument is not used, the calling string is searched from the beginning. |
| substring() |
Syntax: str.substring(indexStart[, indexEnd]) Extracts a substring from the calling string and returns it as a new string. The substring to be extracted starts at the position specified by indexStart and ends at the position immediately before that specified by the optional indexEnd argument. For example.
let str = "All the King's horses ...."; If indexEnd is omitted, slice() extracts all characters from the start position to the end of the string. For example:
let str = "All the King's horses ...."; If indexStart is equal to indexEnd, an empty string is returned. If indexStart is greater than indexEnd, the arguments are swapped around. If indexStart is a negative value, it is treated as if it were zero. Similarly, if indexEnd is greater than str.length, it is treated as if it were str.length. |
| toLocaleLowerCase() |
Syntax:
str.toLocaleLowerCase() Converts the calling string to all lower case characters according to any locale-specific case mappings, and returns the result as a new string. For example:
let str = "Hello World!"; The locale parameter indicates the locale to be used to convert to lower case according to any locale-specific case mappings. If multiple locales are given in an array, the best available locale is used. The default locale is the host environment's current locale. In most cases, this method will produce the same result as toLowerCase(), but for some locales whose case mappings do not follow the default case mappings in Unicode, there may be a different result. |
| toLocaleUpperCase() |
Syntax:
str.toLocaleUpperCase() Converts the calling string to all upper case characters according to any locale-specific case mappings, and returns the result as a new string. For example:
let str = "Hello World!"; The locale parameter indicates the locale to be used to convert to lower case according to any locale-specific case mappings. If multiple locales are given in an array, the best available locale is used. The default locale is the host environment's current locale. In most cases, this method will produce the same result as toLowerCase(), but for some locales whose case mappings do not follow the default case mappings in Unicode, there may be a different result. Note that the conversion to upper case does not always produce a one-to-one character mapping. The conversion of some lower case characters to upper case can produce two (and in some cases more) characters, so the length of the result string can differ from that of the calling string. |
| toLowerCase() |
Syntax: str.toLowerCase() Converts the calling string to all lower case characters and returns the result as a new string. For example:
let str = "Hello World!"; |
| toString() |
Syntax: str.toString() Returns the value of a String object as a string primitive. For example:
let strObj = new String("Hello World!"); Note that using the toString() method with a String object is functionally equivalent to using the valueOf() method with the same String object. |
| toUpperCase() |
Syntax: str.toUpperCase() Converts the calling string to all upper case characters and returns the result as a new string. For example:
let str = "Hello World!"; |
| trim() |
Syntax: str.trim() Removes whitespace characters from both ends of the calling string and returns the result as a new string. For example:
let str = " Hello World! "; Whitespace characters in this context include the space, tab, non-breaking space, and any line terminating characters. |
| valueOf() |
Syntax: str.valueOf() Returns the value of a String object as a string primitive. For example:
let strObj = new String("Hello World!"); Note that using the valueOf() method with a String object is functionally equivalent to using the toString() method with the same String object. |