| Author: | |
| Website: | |
| Page title: | |
| URL: | |
| Published: | |
| Last revised: | |
| Accessed: |
The Document Object Model (DOM) is a platform-independent and language-independent object model and application programming interface (API) for HTML and XML documents. It allows programs and scripts to dynamically access and update the content, structure and style of a document. It describes the objects (or nodes) that make up the document structure, and the interfaces that enable document objects to be accessed and manipulated by scripts and programs. Using the DOM, applications can create HTML or XML documents, and add, modify or delete document objects dynamically.
The DOM has its roots in Dynamic HTML (DHTML), a fairly general term that emerged in the mid 1990s which refers to the use of scripts within an HTML document to implement interactive features on a Web page, from the ubiquitous "rollover" effect to more sophisticated functions such as form validation. Due to intense competition between browser vendors at this time (the height of the so-called Browser Wars), there was scant hope of a standardised approach to creating an interface between scripting languages and the document elements. Netscape Communications released JavaScript in 1996 as part of Netscape Navigator 2.0. Microsoft followed suit later that year with Internet Explorer 3.0 and a scripting language called JScript, which was based on JavaScript. Both vendors implemented a hierarchical document object model to enable scripts to access document elements. Needless to say there were differences in implementation, since no independent standard existed, although this legacy DOM (or DOM Level 0) as it became known, was partly described in the specification for HTML 4.0 in 1997.
The diagram below shows the hierarchy of objects available to JavaScript versions 1.0, 1.1 and 1.2.
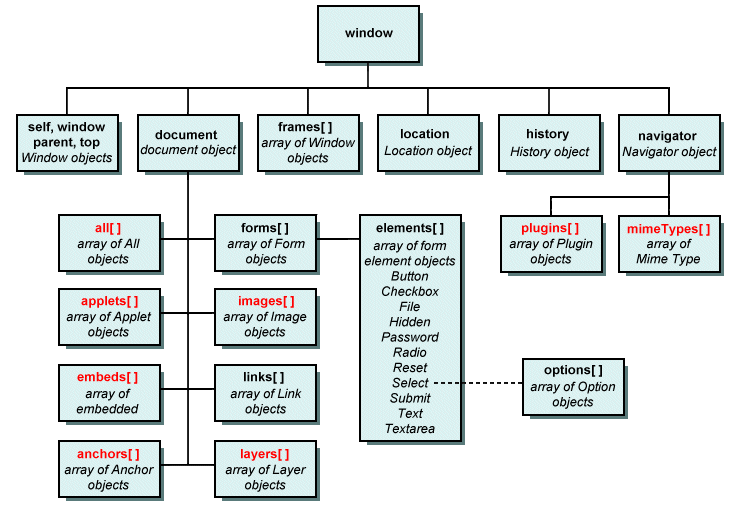
The Document Object Model (DOM Level 0)
In the HTML document shown below, inline JavaScript is used to create a form with a button that, when clicked, invokes a JavaScript function (defined in the head of the document) that displays an Alert box with the message "Hello World!" Although a trivial example, it demonstrates the way in which JavaScript can access the document object model.
<html>
<head>
<script language="JavaScript">
<!--
function functionName() {
alert(text);
}
var text = 'Hello World';
//-->
</script>
</head>
<body>
<script language="JavaScript">
<!--
document.write('<form>' +
'<input type="button" value="Click Here" ' +
'onClick="functionName()"></form>');
//-->
</script>
</body>
</html>
In 1997, version 4.0 of Netscape (Netscape Communicator) and version 4.0 of Microsoft Internet Explorer both added support for Dynamic HTML functionality, allowing changes to be made to a loaded HTML document. This required changes to the Legacy DOM, the different versions of which had, up to that point been largely compatible, since Jscript was based on JavaScript. Unfortunately, both vendors developed extensions independently of one another, leading to a significant degree of incompatibility. These versions of the Document Object Model became known as the Intermediate DOMs. These Intermediate DOMs also enabled the manipulation of Cascading Style Sheet (CSS) properties, allowing the presentational characteristics of documents to be manipulated by scripts. Because of the incompatibility between the competing DOMs, however, Web developers were obliged to write code to handle the differences in implementation, in order to ensure that their pages behaved correctly on all browsers.
W3C collaborated with several of the major browser vendors, including Netscape and Microsoft, to develop a standard for browser scripting languages called ECMAScript, the first version of which was published in 1997. Subsequent releases of JavaScript and JScript were to implement the ECMAScript standard to improve cross-browser compatibility. The first DOM standard, DOM Level 1 was released as a W3C Recommendation in 1998, and provided a comprehensive model for both HTML and XML documents.
DOM Level 2 was published in late 2000. It introduced the getElementById() function, which takes an document element's ID as a parameter and returns a reference to the first object found with the specified ID. It also included an event model to enable system events such as the completion of a document load operation by a browser, or user-initiated events such as a mouse click or form update, to be detected and handled by appropriate event handling routines. Support for XML namespaces and CSS was also added to DOM Level 2. DOM Level 3, published in April 2004, added support for XPath (a language for addressing parts of an XML document) and keyboard event handling, as well as an interface for serialising documents as XML (essentially, this means creating a new document and saving the XML data to it). The W3C DOM models a document as a tree-like structure that consists of a hierarchy of nodes. The diagram below illustrates the model's basic structure.
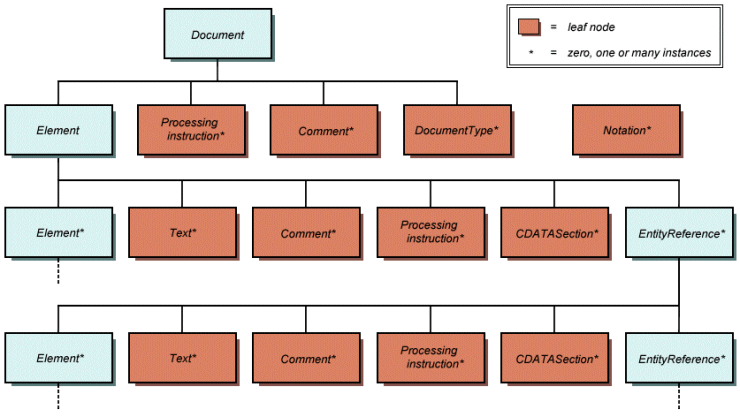
The basic structure of the W3C Document Object Model
The W3C DOM Core specification defines a set of interfaces for accessing and manipulating document objects, and provides sufficient functionality for programmers and Web developers to be able to access and manipulate parsed HTML and XML documents. The DOM Core Application Programming Interface (API) also allows documents to be created and populated using only DOM API calls. Although every object within a document is a node, and inherits the attributes and methods defined for a basic node object, each type of object in a document is represented by its own node object, and implements a specialised interface that adds additional attributes and methods. Some types of node may have child nodes of various types, while others are leaf nodes that cannot have anything below them in the document structure. The node types found in HTML and XML are summarised in the table below.
| Node type | Child nodes allowed |
|---|---|
| Document | Element (1 only), ProcessingInstruction, Comment, DocumentType (one only) |
| DocumentFragment | Element, ProcessingInstruction, Comment, Text, CDATASection, EntityReference |
| DocumentType | None |
| EntityReference | Element, ProcessingInstruction, Comment, Text, CDATASection, EntityReference |
| Element | Element, ProcessingInstruction, Comment, Text, CDATASection, EntityReference |
| Attr | Text, EntityReference |
| ProcessingInstruction | None |
| Comment | None |
| Text | None |
| CDATASection | None |
| Entity | Element, ProcessingInstruction, Comment, Text, CDATASection, EntityReference |
| Notation | None |
The Node interface is the primary datatype for the entire Document Object Model, and represents a single node in the document tree. Note - the DOM also specifies a NodeList interface to dynamically handle ordered lists of nodes, such as the children of a node. Also, although the Attr node inherits methods and attributes of its own from the basic Node object, it represents an attribute within an Element object, and as such the DOM does not consider it to be part of the document tree. Attribute values are represented in the model as simple strings. The objects that do form part of the document tree are described below (note that only Document, Element, Text and Comment nodes are present in HTML documents. The remaining objects all relate to XML documents).
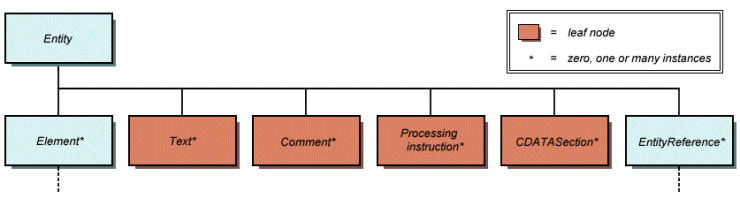
The structure of an Entity
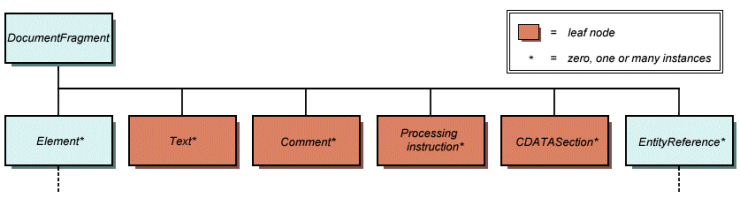
The structure of a DocumentFragment