| Author: | |
| Website: | |
| Page title: | |
| URL: | |
| Published: | |
| Last revised: | |
| Accessed: |
HyperText Transfer Protocol (HTTP) is a connectionless and stateless application-layer protocol that defines how a client computer retrieves content (web pages etc.) from a web server (sometimes called the origin server). The protocol follows a request-response paradigm in which the client computer issues requests which the server responds to. The protocol is said to be connectionless because, although a TCP connection must be established between the client and the server before a request can be sent, once the request has been satisfied the connection is dropped. Furthermore, the protocol has no mechanism for keeping track of the current state of a user transaction, hence it is said to be stateless. Web applications that need to keep track of a user's actions must use other means.
The HTTP client application is called a Web browser (sometimes referred to as a user agent). Communication takes place over a TCP connection, which is established with port 80 on the Web server. When a user initiates a request for a web page by clicking on a link, the browser creates an HTTP request packet which contains, among other things, the uniform resource locator (URL) associated with the link. A software program called a HTTP daemon, which runs on the server and listens to port 80 for incoming traffic, handles HTTP request packets. Between the client computer and the Web server itself, there may be a number of intermediaries involved, such as proxy servers, gateway servers, and tunnels.
Most web resources exist on a server in the form of files of various kinds, but a response may also be created dynamically by a server-side CGI script. All being well the requested resource, including a Content-Type: header that tells the client what kind of data the resource contains, is sent to the client computer. If the web browser recognises the content type it will display the content correctly, if necessary invoking the appropriate plug-in (a plug-in is a software module designed to handle a specific media type that can be called upon by the browser when required).
The first version of HTTP was relatively simple. The browser would request a TCP connection with the server, and send a command such as:
GET / something.html
The command is followed by carriage-return and line-feed characters (CRLF). The server would respond with the contents of the requested file. No request headers were used, and GET was the only method defined. The server would return no additional information, and the protocol was restricted to the retrieval of HTML text documents. Once the document was sent, the server would close the connection. The server terminated each line in the document with a mandatory line-feed character, which could optionally be preceded by a carriage-return. The client computer could not send any data to the server.
HTTP 1.0 introduced new methods and allowed the use of headers in request and response messages, which follow the general format shown below.

The general form of HTTP 1.0 messages
An HTTP request message consists of a request line, optionally followed by one or more header, and an optional entity body which could contain data (for example, form data). The "|" character indicates alternatives. The request line consists of the method name, the path to the requested resource, and the version of HTTP being used. A typical request line might appear as follows:
GET /path_to_file/index.html HTTP/1.0
An HTTP response message is similar to the request message except that a status line replaces the request line. The status line contains the HTTP version, a status code that indicates whether or not the request was successful, and a brief status description. Two typical status lines are shown below.
HTTP/1.0 200 OK
HTTP/1.0 404 Not Found
HTTP 1.0 allowed access to certain resources to be restricted to users with a valid username and password. A status code of 401 in a response, for example, indicates that the user is not authorised to view the resource they have requested.
Request headers can be used by a client to specify the preferred content type, or to specify conditional retrieval (for example, so that a resource will only be returned if it has changed since a given date). Response headers can be used by the server to specify the type of content being returned. The body of a response message may contain the requested file, the result of a user query, or some other (often dynamically generated) response from the server.
HTTP 1.0 introduced the HEAD method, which allows a client to retrieve only the file header information without actually retrieving the file itself, and the POST method, which allows a client to send a significant amount of information (such as the data entered into a form by a user) to the server. The data sent to the server will often be passed to a CGI script to be processed in some way, and will often result in a dynamically-generated response. A typical form submission is shown below.
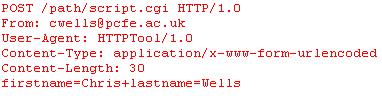
A typical form submission
The most recent version of HTTP is version 1.1 (RFC 2616, 1999). Basic operation is the same as for HTTP 1.0, but a number of new features have been added, some of the more important of which are described below.
A proxy server receives a HTTP request from a client computer and forwards it to the appropriate web server on behalf of the client, maintaining the anonymity of the client. The web server sends the response to the proxy server, which forwards it to the client. The proxy may store a copy of the response in its cache for a period of time, from which it can service additional requests for the same resource. This has the effect of reducing the overall amount of Internet traffic and speeding up response times. The proxy can make a conditional request to the server, following receipt of which the server will return the requested document only if the proxy does not already have an up-to-date version in its cache. The origin server may also include an Expires: header with any resource returned that provides a time frame within which the proxy may consider the resource to be current. The client can, if required, specify that a request should not be satisfied from a cache, or may specify the maximum acceptable age of a cached response.
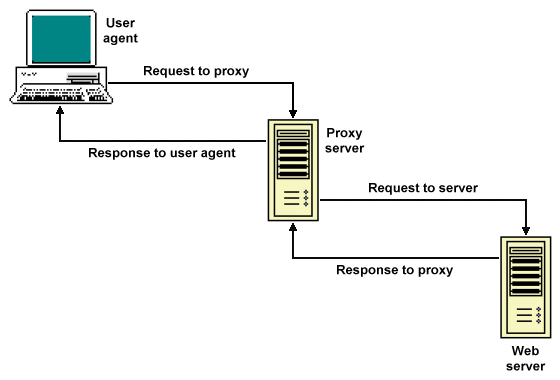
A proxy server relays client requests to a web server
Basic authentication is a challenge-response access control mechanism in which a user's password is sent in clear text across a network. An alternative method called digest authentication, developed in parallel with HTTP 1.1, employs a password known only to client and server. The client computes a digest value using the Message Digest 5 (MD5) algorithm. The value is computed using a combination of the username and password, and several values related to the requested resource. It may also be time-dependent. The computed digest value is then sent across the network to the server, which applies the MD5 algorithm to the received digest value, and can verify its authenticity using the information it holds about the client. Digest authentication is far more secure than basic authentication. The dominant method of establishing a secure HTTP connection is to use the HTTPS URL scheme, which is syntactically identical to that used for normal HTTP connections, but which signals the browser to use an added encryption layer - either Secure Sockets Layer (SSL) or Transport Layer Security (TLS). SSL is particularly suited for HTTP because it provides some protection even if only one end of the connection (typically the server) is authenticated.
From the server's point of view, all HTTP requests are stateless in that each request is considered to be independent of any other request. This model conflicts with the need that many Web applications have for keeping track of user activity. An online shopping application, for example, must keep track of what is in the user's shopping cart. Many Web applications store state information in "cookies". These are small data files which are stored on the client computer, and which are updated by the Web application as the user interacts with it. The server includes updated state information in its response to the client, which saves the information in a cookie. The data held in the cookie is sent by the client to the server as part of the next request. An application can assign an expiration time and date to a cookie, after which it may not be used. Cookies may contain sensitive information such as credit card details, passwords, and personal details. As such, they represent a potential security risk, since they may be accessed by a hacker (or some autonomous agent) gaining unauthorised access to the client system. Alternative methods of state management that do not involve the use of cookies are provided by application environments like Microsoft's Active Server Pages (ASP), Sun Microsystems' Java Server Pages (JSP), and the open-source PHP server-side scripting environment.
Both request and response messages may include an entity consisting of entity header fields and an entity body. The entity body differs from the message body only if a transfer encoding has been applied to it. The presence of a message body in a request is indicated by the inclusion of a Content-Length or Transfer-Encoding header field. A response to a request that uses the HEAD method will not include a message body, even though it may well include a number of entity header fields. Most other response messages will, of course, include a message body, which will consist of all or part of the requested resource (or user data sent from the client to the server). The entity header fields provide meta-information about the entity body (or about the resource identified by the request, if the HEAD method has been used).
When an entity body is included with a message, the media type of the underlying data is specified by the header field Content-Type, while the Content-Length header specifies the length of the data in bytes. The Content-Encoding header is used to specify any additional encoding that has been applied to the entity body (such encoding is primarily used to allow a document to be compressed), and enables the client to determine the correct decoding mechanism to apply.
The HTTP response status line includes a machine-readable 3-digit status code, followed by a human-readable reason phrase. How the user agent deals with the response depends on the code and the response headers. If the status code indicates a problem, the user agent will usually display the reason phrase to the user to inform them of the nature of the problem. The general class of the status code is determined by the first digit, as follows:
The status codes defined for HTTP 1.1 are listed in the table below (the reason phrases shown are recommendations only, and may be safely replaced with locally defined messages).
| Code | Reason phrase |
|---|---|
| 100 | Continue |
| 101 | Switching Protocols |
| 200 | OK |
| 201 | Created |
| 202 | Accepted |
| 203 | Non-Authoritative Information |
| 204 | No Content |
| 205 | Reset Content |
| 206 | Partial Content |
| 300 | Multiple Choices |
| 301 | Moved Permanently |
| 302 | Found |
| 303 | See Other |
| 304 | Not Modified |
| 305 | Use Proxy |
| 307 | Temporary Redirect |
| 400 | Bad Request |
| 401 | Unauthorized |
| 402 | Payment Required |
| 403 | Forbidden |
| 404 | Not Found |
| 405 | Method Not Allowed |
| 406 | Not Acceptable |
| 407 | Proxy Authentication Required |
| 408 | Request Time-out |
| 409 | Conflict |
| 410 | Gone |
| 411 | Length Required |
| 412 | Precondition Failed |
| 413 | Request Entity Too Large |
| 414 | Request-URI Too Large |
| 415 | Unsupported Media Type |
| 416 | Requested range not satisfiable |
| 417 | Expectation Failed |
| 500 | Internal Server Error |
| 501 | Not Implemented |
| 502 | Bad Gateway |
| 503 | Service Unavailable |
| 504 | Gateway Time-out |
| 505 | HTTP Version not supported |