| Author: | |
| Website: | |
| Page title: | |
| URL: | |
| Published: | |
| Last revised: | |
| Accessed: |
In order to display a web page correctly, your web browser needs to know what character set to use. In the early days of the World Wide Web this was not really a problem, because the only character set used for web pages was the 128-character ASCII character set.
Within a decade, however, the web had become a truly worldwide phenomenon, and the resulting demand for internationalisation led to the development of a number of disparate and largely incompatible international character sets. It soon became obvious that some kind of international standard was needed.
ASCII (sometimes referred to as US-ASCII) is the abbreviation for the American Standard Code for Information Interchange, a character encoding standard developed for electronic communication and based on typographical symbols predominantly used in the United States. The ASCII standard was first published in 1963 and was most recently updated in 1986. ASCII has been widely-used to represent text in computers and telecommunications devices.
The table below lists the ASCII characters together with their decimal and hexadecimal code points. It also gives the named HTML entity used to represent a character, if one exists. Note that a numeric HTML entity exists for every printable character in the ASCII character set. It consists of an ampersand (&) followed by a hash sign (#) and then the decimal code point followed by a semi-colon (;). The upper-case character 'A' would thus be represented as follows:
A
The hexadecimal code point can also be used. The format is the same, except that an 'x' precedes the hexadecimal code to indicate that a hexadecimal code point is being used. Here is the hexadecimal numeric HTML entity for the upper-case character 'A':
A
The use of HTML entities is normally only required for characters that have special meaning within the HTML code itself, like the quotation mark, apostrophe, ampersand, less than, and greater than sympols (we have highlighted the corresponding entity names in the table).
| Dec | Hex | Char | CTRL CHR/ HTML entity name | Dec | Hex | Char | HTML entity name |
|
|---|---|---|---|---|---|---|---|---|
| 000 | 00 | - | NUL | 064 | 40 | @ | @ | |
| 001 | 01 | - | SOH | 065 | 41 | A | - | |
| 002 | 02 | - | STX | 066 | 42 | B | - | |
| 003 | 03 | - | ETX | 067 | 43 | C | - | |
| 004 | 04 | - | EOT | 068 | 44 | D | - | |
| 005 | 05 | - | ENQ | 069 | 45 | E | - | |
| 006 | 06 | - | ACK | 070 | 46 | F | - | |
| 007 | 07 | - | BEL | 071 | 47 | G | - | |
| 008 | 08 | - | BS | 072 | 48 | H | - | |
| 009 | 09 | - | HT | 073 | 49 | I | - | |
| 010 | 0A | - | LF | 074 | 4A | J | - | |
| 011 | 0B | - | VT | 075 | 4B | K | - | |
| 012 | 0C | - | FF | 076 | 4C | L | - | |
| 013 | 0D | - | CR | 077 | 4D | M | - | |
| 014 | 0E | - | SO | 078 | 4E | N | - | |
| 015 | 0F | - | SI | 079 | 4F | O | - | |
| 016 | 10 | - | DLE | 080 | 50 | P | - | |
| 017 | 11 | - | DC1 | 081 | 51 | Q | - | |
| 018 | 12 | - | DC2 | 082 | 52 | R | - | |
| 019 | 13 | - | DC3 | 083 | 53 | S | - | |
| 020 | 14 | - | DC4 | 084 | 54 | T | - | |
| 021 | 15 | - | NAK | 085 | 55 | U | - | |
| 022 | 16 | - | SYN | 086 | 56 | V | - | |
| 023 | 17 | - | ETB | 087 | 57 | W | - | |
| 024 | 18 | - | CAN | 088 | 58 | X | - | |
| 025 | 19 | - | EM | 089 | 59 | Y | - | |
| 026 | 1A | - | SUB | 090 | 5A | Z | - | |
| 027 | 1B | - | ESC | 091 | 5B | [ | [ | |
| 028 | 1C | - | FS | 092 | 5C | \ | \ | |
| 029 | 1D | - | GS | 093 | 5D | ] | ] | |
| 030 | 1E | - | RS | 094 | 5E | ^ | ^ | |
| 031 | 1F | - | US | 095 | 5F | _ | _ | |
| 032 | 20 | - | 096 | 60 | ` | ` | ||
| 033 | 21 | ! | ! | 097 | 61 | a | - | |
| 034 | 22 | " | " | 098 | 62 | b | - | |
| 035 | 23 | # | # | 099 | 63 | c | - | |
| 036 | 24 | $ | $ | 100 | 64 | d | - | |
| 037 | 25 | % | % | 101 | 65 | e | - | |
| 038 | 26 | & | & | 102 | 66 | f | - | |
| 039 | 27 | ' | ' | 103 | 67 | g | - | |
| 040 | 28 | ( | ( | 104 | 68 | h | - | |
| 041 | 29 | ) | ) | 105 | 69 | i | - | |
| 042 | 2A | * | * * | 106 | 6A | j | - | |
| 043 | 2B | + | + | 107 | 6B | k | - | |
| 044 | 2C | , | , | 108 | 6C | l | - | |
| 045 | 2D | - | − | 109 | 6D | m | - | |
| 046 | 2E | . | . | 110 | 6E | n | - | |
| 047 | 2F | / | / | 111 | 6F | o | - | |
| 048 | 30 | 0 | - | 112 | 70 | p | - | |
| 049 | 31 | 1 | - | 113 | 71 | q | - | |
| 050 | 32 | 2 | - | 114 | 72 | r | - | |
| 051 | 33 | 3 | - | 115 | 73 | s | - | |
| 052 | 34 | 4 | - | 116 | 74 | t | - | |
| 053 | 35 | 5 | - | 117 | 75 | u | - | |
| 054 | 36 | 6 | - | 118 | 76 | v | - | |
| 055 | 37 | 7 | - | 119 | 77 | w | - | |
| 056 | 38 | 8 | - | 120 | 78 | x | - | |
| 057 | 39 | 9 | - | 121 | 79 | y | - | |
| 058 | 3A | : | : | 122 | 7A | z | - | |
| 059 | 3B | ; | ; | 123 | 7B | { | { | |
| 060 | 3C | < | < | 124 | 7C | | | | | |
| 061 | 3D | = | = | 125 | 7D | } | } | |
| 062 | 3E | > | > | 126 | 7E | ~ | - | |
| 063 | 3F | ? | ? | 127 | 7F | - | DEL |
ASCII uses a 7-bit character encoding (the eighth bit was originally reserved for parity checking). This allows a total of one hundred and twenty-eight characters to be encoded. The first thirty-two characters are non-printing control characters (now mostly obsolete) used in data transmission, or to control devices such as printers. The last character (127 or 7Fhex is the delete (DEL) control character.
The ninety-five remaining code points (32 to 126 or 20hex to 7Ehex) all represent printable characters, including the digits 0 to 9, the lowercase letters a to z, the uppercase letters A to Z, a number of punctuation symbols and other symbols, and the space character. The ASCII character set forms the basis for more recent character encoding standards such as ISO-8859 and UTF-8.
The default character set for the HTML 4.0 standard which emerged towards the end of the 1990s was based on the ISO/IEC 8859 series of standards for 8-bit character encodings. Unlike ASCII, ISO/IEC 8859 used all eight bits to encode characters and was thus able to represent twice as many characters.
The first 128 characters were identical to those in the ASCII character set, making ISO/IEC 8859 a superset of ASCII. Characters 128-159 were reserved for control characters. The remaining 96 places were intended for non-ASCII characters used by other languages based on the classical Latin alphabet.
Because the number of extra characters required to support these languages far exceeded the 96 places available, the ISO/IEC 8859 standard consisted of fifteen separate parts: ISO/IEC 8859-1 - ISO/IEC 8859-16 (ISO/IEC 8859-12 was abandoned). Each part was intended for use with a different set of languages.
The table below gives a brief summary of the ISO/IEC 8859 series of standards. The left-hand column shows year in which the current version of the corresponding part was published. The year in which the original version was published, if applicable, is shown in parentheses.
| Part | Name | Language support |
|---|---|---|
| Part 1 1998 (1987) |
Latin-1 (Western European) ISO/IEC 8859-1 |
Danish (partial), Dutch (partial), English, Faeroese, Finnish (partial), French (partial), German, Icelandic, Irish, Italian, Norwegian, Portuguese, Rhaeto-Romanic, Scottish Gaelic, Spanish, Catalan, Swedish, Albanian, Southeast Asian Indonesian, Afrikaans, Swahili. Revised as ISO/IEC 8859-15 in 1999. |
| Part 2 1999 (1987) |
Latin-2 (Central European) ISO/IEC 8859-2 |
Bosnian, Polish, Croatian, Czech, Slovak, Slovene, Serbian, Hungarian. |
| Part 3 1999 (1988) |
Latin-3 (South European) ISO/IEC 8859-3 |
Turkish, Maltese, Esperanto. Largely superceded by ISO/IEC 8859-9 for Turkish. |
| Part 4 1998 (1988) |
Latin-4 (North European) ISO/IEC 8859-4 |
Estonian, Latvian, Lithuanian, Greenlandic, Sami. |
| Part 5 1999 (1988) |
Latin/Cyrillic ISO/IEC 8859-5 |
Belarusian, Bulgarian, Macedonian, Russian, Serbian, Ukrainian (partial). |
| Part 6 1999 (1987) |
Latin/Arabic ISO/IEC 8859-6 |
Covers most common Arabic language characters. |
| Part 7 2003 (1987) |
Latin/Greek ISO/IEC 8859-7 |
Modern Greek, Ancient Greek (limited to monotonic orthography). |
| Part 8 1999 (1988) |
Latin/Hebrew ISO/IEC 8859-8 |
Covers the modern Hebrew alphabet as used in Israel. |
| Part 9 1999 (1989) |
Latin-5 (Turkish) ISO/IEC 8859-9 |
Turkish (similar to ISO/IEC 8859-1, but with Turkish characters replacing Icelandic characters). |
| Part 10 1998 (1992) |
Latin-6 (Nordic) ISO/IEC 8859-10 |
Nordic languages. |
| Part 11 2001 |
Latin/Thai ISO/IEC 8859-11 |
Contains characters needed for the Thai language. |
| Part 13 1998 |
Latin-7 (Baltic Rim) ISO/IEC 8859-13 |
Baltic languages. |
| Part 14 1998 |
Latin-8 (Celtic) ISO/IEC 8859-14 |
Celtic languages such as Gaelic and the Breton language. |
| Part 15 1999 |
Latin-9 ISO/IEC 8859-15 |
A revision of 8859-1 that removes seldom-used symbols and adds the euro sign € and the letters Š, š, Ž, ž, Œ, œ, and Ÿ (completes coverage of French, Finnish and Estonian). |
| Part 16 2001 |
Latin-10 (South-Eastern European) ISO/IEC 8859-16 |
Albanian, Croatian, Hungarian, Italian, Polish, Romanian, Slovene, Finnish, French, German, Irish Gaelic. |
The default character set for HTML 4 was the Latin 1 (Western European) character set ISO/IEC 8859-1. To use a different character set, it was necessary to explicitly specify the character encoding to be used - for example by using a meta element with the charset parameter, or by using the http-equiv and content attributes within the document's <head> tag).
For the majority of languages, the required character repertoire could be found in a single part of the standard, but this was not true in every case. Moreover, a number of East Asian languages, including Chinese, Japanese and Korean, are not represented at all in the ISO/IEC 8859 system. These shortcomings would be addressed by the development of the Unicode standard.
The table below lists characters 128 – 255 in the ISO/IEC 8859-1 repertoire together with their decimal and hexadecimal code points and named HTML entities. Numeric HTML entities exist for every printable character in the ISO/IEC 8859-1 repertoire and can be derived in the manner described for ASCII printable characters (see above).
| Dec | Hex | Char | CTRL CHR/ HTML entity name | Dec | Hex | Char | HTML entity name |
|
|---|---|---|---|---|---|---|---|---|
| 128 | 80 | - | PAD | 192 | C0 | À | À | |
| 129 | 81 | - | HOP | 193 | C1 | Á | Á | |
| 130 | 82 | - | BPH | 194 | C2 | Â | Â | |
| 131 | 83 | - | NBH | 195 | C3 | Ã | Ã | |
| 132 | 84 | - | IND | 196 | C4 | Ä | Ä | |
| 133 | 85 | - | NEL | 197 | C5 | Å | Å | |
| 134 | 86 | - | SSA | 198 | C6 | Æ | Æ | |
| 135 | 87 | - | ESA | 199 | C7 | Ç | Ç | |
| 136 | 88 | - | HTS | 200 | C8 | È | È | |
| 137 | 89 | - | HTJ | 201 | C9 | É | É | |
| 138 | 8A | - | VTS | 202 | CA | Ê | Ê | |
| 139 | 8B | - | PLD | 203 | CB | Ë | Ë | |
| 140 | 8C | - | PLU | 204 | CC | Ì | Ì | |
| 141 | 8D | - | RI | 205 | CD | Í | Í | |
| 142 | 8E | - | SS2 | 206 | CE | Î | Î | |
| 143 | 8F | - | SS3 | 207 | CF | Ï | Ï | |
| 144 | 90 | - | DCS | 208 | D0 | Ð | Ð | |
| 145 | 91 | - | PU1 | 209 | D1 | Ñ | Ñ | |
| 146 | 92 | - | PU2 | 210 | D2 | Ò | Ò | |
| 147 | 93 | - | STS | 211 | D3 | Ó | Ó | |
| 148 | 94 | - | CCH | 212 | D4 | Ô | Ô | |
| 149 | 95 | - | MW | 213 | D5 | Õ | Õ | |
| 150 | 96 | - | SPA | 214 | D6 | Ö | Ö | |
| 151 | 97 | - | EPA | 215 | D7 | × | × | |
| 152 | 98 | - | SOS | 216 | D8 | Ø | Ø | |
| 153 | 99 | - | SGC1 | 217 | D9 | Ù | Ù | |
| 154 | 9A | - | SCI | 218 | DA | Ú | Ú | |
| 155 | 9B | - | CSI | 219 | DB | Û | Û | |
| 156 | 9C | - | SC | 220 | DC | Ü | Ü | |
| 157 | 9D | - | OST | 221 | DD | Ý | Ý | |
| 158 | 9E | - | PM | 222 | DE | Þ | Þ | |
| 159 | 9F | - | APC | 223 | DF | ß | ß | |
| 160 | A0 | | 224 | E0 | à | à | ||
| 161 | A1 | ¡ | ¡ | 225 | E1 | á | á | |
| 162 | A2 | ¢ | ¢ | 226 | E2 | â | â | |
| 163 | A3 | £ | £ | 227 | E3 | ã | ã | |
| 164 | A4 | ¤ | ¤ | 228 | E4 | ä | ä | |
| 165 | A5 | ¥ | ¥ | 229 | E5 | å | å | |
| 166 | A6 | ¦ | ¦ | 230 | E6 | æ | æ | |
| 167 | A7 | § | § | 231 | E7 | ç | ç | |
| 168 | A8 | ¨ | ¨ | 232 | E8 | è | è | |
| 169 | A9 | © | © | 233 | E9 | é | é | |
| 170 | AA | ª | ª | 234 | EA | ê | ê | |
| 171 | AB | « | « | 235 | EB | ë | ë | |
| 172 | AC | ¬ | ¬ | 236 | EC | ì | ì | |
| 173 | AD | | ­ | 237 | ED | í | í | |
| 174 | AE | ® | ® | 238 | EE | î | î | |
| 175 | AF | ¯ | ¯ | 239 | EF | ï | ï | |
| 176 | B0 | ° | ° | 240 | F0 | ð | ð | |
| 177 | B1 | ± | ± | 241 | F1 | ñ | ñ | |
| 178 | B2 | ² | ² | 242 | F2 | ò | ò | |
| 179 | B3 | ³ | ³ | 243 | F3 | ó | ó | |
| 180 | B4 | ´ | ´ | 244 | F4 | ô | ô | |
| 181 | B5 | µ | µ | 245 | F5 | õ | õ | |
| 182 | B6 | ¶ | ¶ | 246 | F6 | ö | ö | |
| 183 | B7 | · | · | 247 | F7 | ÷ | ÷ | |
| 184 | B8 | ¸ | ¸ | 248 | F8 | ø | ø | |
| 185 | B9 | ¹ | ¹ | 249 | F9 | ù | ù | |
| 186 | BA | º | º | 250 | FA | ú | ú | |
| 187 | BB | » | » | 251 | FB | û | û | |
| 188 | BC | ¼ | ¼ | 252 | FC | ü | ü | |
| 189 | BD | ½ | ½ | 253 | FD | ý | ý | |
| 190 | BE | ¾ | ¾ | 254 | FE | þ | þ | |
| 191 | BF | ¿ | ¿ | 255 | FF | ÿ | ÿ |
Windows-1252 (or CP-1252) is an 8-bit character encoding scheme for the Latin alphabet that was developed by Microsoft and is the default encoding scheme for versions of the Microsoft Windows operating system and other Microsoft software intended for use with English and some other Western languages. Although almost identical to ISO 8859-1, Windows-1252 has never been an ANSI or ISO standard.
Because of the former popularity of Windows-1252 (at one time probably one of the most widely used character encoding schemes in the world) the charset label "windows-1252" is still recognised by most if not all browsers, although probably less than one percent of web sites worldwide now declare the use of Windows-1252.
As for ISO 8859-1, the first 128 characters in Windows-252 (i.e. code points 0-127) are identical to those in the ASCII character set. Windows-1252 is a thus a superset of ASCII. In fact, it differs from ISO 8859-1 only in its use of printable characters rather than control characters for code points 128 through 159. A summary of these characters is shown in the table below.
| Dec | Hex | Char | CTRL CHR/ HTML entity name | Dec | Hex | Char | HTML entity name |
|
|---|---|---|---|---|---|---|---|---|
| 128 | 80 | € | € | 144 | 90 | - | - | |
| 129 | 81 | - | - | 145 | 91 | ‘ | ‘ | |
| 130 | 82 | ‚ | ‚ | 146 | 92 | ’ | ’ | |
| 131 | 83 | ƒ | ƒ | 147 | 93 | “ | “ | |
| 132 | 84 | „ | „ | 148 | 94 | ” | ” | |
| 133 | 85 | … | … | 149 | 95 | • | • | |
| 134 | 86 | † | † | 150 | 96 | – | – | |
| 135 | 87 | ‡ | ‡ | 151 | 97 | — | — | |
| 136 | 88 | ˆ | ˆ | 152 | 98 | ˜ | ˜ | |
| 137 | 89 | ‰ | ‰ | 153 | 99 | ™ | ™ | |
| 138 | 8A | Š | Š | 154 | 9A | š | š | |
| 139 | 8B | ‹ | ‹ | 155 | 9B | › | › | |
| 140 | 8C | Œ | Œ | 156 | 9C | œ | œ | |
| 141 | 8D | - | - | 157 | 9D | - | - | |
| 142 | 8E | Ž | Ž | 158 | 9E | ž | ž | |
| 143 | 8F | - | - | 159 | 9F | Ÿ | Ÿ |
The code point representations shown in the above table are those used in the final version of Windows-1252, which made its first appearance in Windows 98, and was subsequently ported to older versions of Windows.
In terms of printable characters, Windows-1252 can be considered to be a superset of ISO 8859-1. In additional to all of the printable characters in ISO 8559-1, Windows-1252 includes curly quotation marks, and all of the printable characters in ISO 8859-15 that were not included in ISO 8859-1 (albeit in different positions).
Windows-1252 characters have in the past been included in web pages that claimed to use the charset ISO 8859-1 charset. This can occur, for example, when text containing "smart quotes" is created in Microsoft Word and then pasted into an HTML document. The quotation marks and apostrophes are subsequently read by the browser as control characters and are displayed incorrectly.
There are still a significant number of websites in existence that make use of Windows-1252 characters, but incorrectly identify the charset as ISO 8859-1. The default behaviour of most browsers, whenever they encounter a reference to ISO 1885-1, is to parse the text as if the charset has been declared as Windows-1252. This ensures that any non-ISO 8859-1 characters will be correctly displayed.
In 1987, three software engineers – Joe Becker, Lee Collins and Mark Davis – initiated a project to develop a universal character encoding scheme which they called Unicode. The project led to the incorporation of the Unicode Consortium in California in 1991, whose stated aim was to develop, extend, and promote the use of the Unicode Standard.
The Unicode Standard claims to include encodings for (almost) every character, punctuation mark and symbol used by every language in the world. It is supported by current versions of virtually every operating system and web browser. The encoding scheme used is called the Unicode Transformation Format (UTF) and has several variants. The most relevant variant from the point of view of developing web pages is UTF-8.
UTF-8 is a variable-width encoding scheme that can use from one to four 8-bit bytes to represent any character in the Unicode repertoire. Like each of the ISO 8559 standards that preceded it, it is a superset of ASCII. It is also a superset of the ISO 8559 standards. The World Wide Web Consortium (W3C) guidelines on Internationalisation techniques, under the heading Choosing and applying a character encoding, now advises web authors to choose UTF-8 for all content.
The first 256 characters of Unicode character sets (including UTF-8) are identical to the 256 characters of ISO 8859-1. This represents just a tiny fraction, however, of the total code space available. Unicode has a total of 1,114,112 code points! the Unicode code space is divided into seventeen planes (the basic multilingual plane plus sixteen supplementary planes), each of which contains 65,536 (2 16) code points.
Unicode version 12.1 (released in May 2019) defines a total of 137, 994 encoded characters with unique identifying names, although it should be noted that more complex characters and symbols (emojis, for example) can be created using a combination of two or more characters from this code space. It is therefore not possible to calculate the actual number of character representations possible with Unicode.
What we can say is that UTF-8 can represent every character within the Universal Coded Character Set (UCS), which is defined by the international standard ISO/IEC 10646. This is the character repertoire now used by HTML. Each character in the ISO/IEC 10646 repertoire is identified by an unambiguous name and a unique numeric value (its code point). The ISO/IEC 10646 standard is maintained in tandem with the Unicode standard, and both standards share the same set of unique code points.
Each Unicode code point is (usually) written as a five-digit hexadecimal number including leading zeros, prefixed with an upper-case "U" followed by a plus sign. For example, the uppercase letter "E", which has the decimal code point 69 (45h), would be written as follows:
U+00045
Most web pages today specify the use of the UTF-8 encoding scheme, because it can represent all of the characters used by virtually every language in the world, as well as a huge range of symbols and characters used in areas such as mathematics and science. To some extent, this has eliminated the need to use HTML entity references (which we will talk about shortly) since any character in the UTF-8 repertoire will be rendered correctly by modern browsers.
Each plane of the Unicode code space is further subdivided into Unicode blocks. A block is a contiguous range of code points, and each block has a unique descriptive name. The number of code points in any Unicode block is always a multiple of 16. Blocks can vary in size, from a minimum size of 16 code points up to a maximum size of 65,536 code points.
At the time of writing, all of the named HTML entity names published by the W3C refer to code points belonging to Unicode blocks contained within the Basic Multilingual Plane (BMP) except for those that refer to characters in the Mathematical Alphanumeric Symbols block, which is part of the Supplementary Multilingual Plane (SMP).
The default character encoding for HTML5, and the one recommended by the World Wide Web Consortium for all content, is UTF-8. Having said that, there is nothing to prevent you from using alternative character encodings should you (for whatever reason) feel the need to do so.
Whichever character encoding standard you decide to use, you should always declare it in the head of your HTML documents in order to ensure that a web browser will render your pages correctly. If you don't specify a character encoding, the browser will either assume the default encoding for HTML 5 or use the encoding (if any) specified in the HTTP header. Which brings us to a rather tricky point.
The character encoding declared in the web server's HTTP header when it delivers your content will override any character encoding you specify in your HTML document. If your chosen character encoding differs from the character encoding specified by the web server's HTTP header, a web browser may not display all of your text correctly.
We'll come back to that point shortly. Before we do, let's look at how we actually declare our chosen character encoding within the HTML document itself. The W3C has this to say:
"Always declare the encoding of your document using a meta element with a charset attribute, or using the http-equiv and content attributes (called a pragma directive). The declaration should fit completely within the first 1024 bytes at the start of the file, so it's best to put it immediately after the opening head tag."
Both of the following declarations do exactly the same thing:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
. . .
</head>
<!DOCTYPE html>
<html lang="en">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
. . .
</head>
According to the W3C, it doesn't matter which one you use (although we prefer the first option because its shorter and easier to remember). One other point here is of paramount importance: you must ensure that the HTML file is saved with the same character encoding you have declared for the document. Most HTML editors will allow you to choose the encoding to be used when saving a file; the default encoding is usually UTF-8, but you might want to check, just to make sure.
Now let's tackle the issue of the HTTP header. As stated earlier, any character encoding declared in the HTTP header used by the web server to serve your documents will override the character encoding declaration used in your HTML document; this is obviously not an issue if they are both the same. If they are not, then what can you do about it? There are a couple of options available to you.
If you have administrative access to the server settings, you could change the character encoding declared by the HTTP header to match that of your HTML documents. Note that you should still declare the character encoding in the head of your HTML file, as it will be used by user agents when rendering your document in offline mode. You must also make sure that the character encoding declared in your document matches the character encoding used in the HTTP header.
If you do not have access to the web server settings (this is likely to be the case if you are using a web hosting service, for example) you may still be able to override the default "Content-Type" HTTP settings using a file called .htaccess, which you would need to create and upload to your website's root directory. Using the Header directive within the .htaccess file allows you to add, modify or delete HTTP response headers.
A detailed discussion of how you would go about implementing either of the above solutions is beyond the scope of this page. The good news is that if you stick to using UTF-8, there shouldn't be a problem, since most web servers don't specify a charset, and most of those that do specify UTF-8 by default.
One final point relates to something called the byte order mark or BOM. This is a two-byte code that is sometimes included in HTML files that use a Unicode character encoding. Before the advent of UTF-8 in 1993, all Unicode characters were transmitted as 16-bit code units with either the most significant byte first or the least significant byte first, depending on the order in which they were stored in memory. The BOM was added to the beginning of a transmission to indicate the byte order being used.
If there is a byte order mark at the beginning of an HTML file, most modern browsers will interpret this as meaning that the character encoding used by the document is UTF-8. Furthermore, this will (in the majority of cases) override any character encoding declared elsewhere, including the HTTP Content-type header.
You can check for the presence of a BOM at the start of a web page using the W3C Internationalization Checker. Enter the URL of the page you want to check, then click on the Check button. Details of the document's character encoding, including the presence or absence of a byte order mark, will be shown in the Character encoding section of the Internationalization Checker's output, as illustrated below.
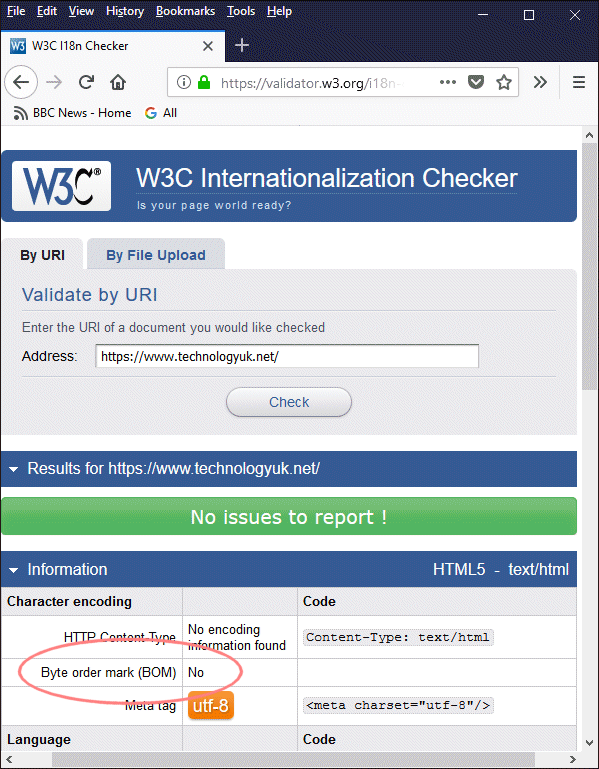
W3C's Internationalization Checker will indicate whether a BOM is present
Note that the Unicode standard allows, but does not require or recommend, the use of a byte order mark for UTF-8. It does not recommend removing a BOM if present, because some code may require it in order to function correctly. A number of Microsoft applications - Notepad for example - add a BOM when saving text as UTF-8 and will be unable to interpret UTF-8 text correctly unless the BOM is present (or the file consists purely of ASCII characters).
The byte order mark can cause problems for some legacy software that does not know how to handle it, although these problems are gradually disappearing with the adoption of up-to-date browsers and HTML editing programs. Perhaps of more concern, though not something we need to worry about just yet, is that the presence of a BOM in files used by some scripting languages can sometimes cause unwanted side effects.
HTML character references provide an alternative means of representing characters in your HTML code. Essentially, since UTF-8 can be used to represent every code point in the Unicode code space, the only characters you must use an HTML entity for are the HTML reserved characters - ampersand (&), less-than (<), and greater-than (>). There are other circumstances, however, where the use of HTML character references may be necessary (or simply more convenient).
In HTML documents, each character used can either represent itself directly or be represented by a sequence of characters called a character reference. There are two types of character reference - a numeric character reference and a character entity reference. A numeric character reference uses the character's Unicode code point expressed as a decimal or hexadecimal number, whereas a character entity reference uses a unique entity name.
The following character references all represent the Greek capital letter Omega (Ω):
Ω <!-- decimal numeric character reference -->
Ω <!-- hexadecimal numeric character reference -->
Ω <!—character entity reference -->
Note the format for each representation. All HTML character references begin with the ampersand character (&) and end with a semi-colon (;). Numeric character references must include either the decimal representation of the character's code point prefixed with a hash sign (#), or the hexadecimal representation of the character's code point prefixed with a hash sign plus the lowercase letter "x". Leading zeros are ignored.
Named entities must include the unique W3C-defined symbolic name that refers to the character. Note that entity names are case sensitive. Note also that, in a number of cases, there may be two or more names defined for the same Unicode character (the reasons for this are probably historical; it doesn't seem to matter which name is used).
At the time of writing, W3C defines names for 1450 Unicode characters (and yes, we did count them - twice in fact), although the current list is a work in progress. We present a list of the named entities, in Unicode code point order and organised by Unicode block (see above) at the bottom of this page. As far as we have been able to ascertain (by carrying out a number of random checks), numeric character references can be used for any currently defined Unicode character.
The arguments for and against the use of HTML character references are many and varied, and a detailed discussion of the relative merits thereof is beyond the scope of this page. The general consensus seems to be that you should use actual Unicode characters (as opposed to HTML character references) wherever possible. This has the advantage of reducing document size and making your HTML code easier to read.
The use of Unicode characters is obviously conditional on code editors, browsers, and other related software providing support for Unicode. It is also imperative to save your HTML document in the correct (i.e. UTF-8) format, and to declare the character encoding as UTF-8 within the document's <head> element.
Use the links below to view listings of commonly used Unicode code blocks. Each listing includes the HTML numeric entity reference and entity name (if applicable) for each code point in the block, together with a brief description. Characters are listed in ascending numerical order according to their Unicode code point value. NOTE: before using an entity reference in your HTML pages, it is worth checking whether it is supported by popular browsers, as support can vary (particular care should be taken, for example, when using combining diacritical marks).